
Chapitres traités
Date de modification : 08-Mai-2006
Bonjour ŕ tous, aprčs de longues vacances bien méritées, je suis de retour pour vous expliquer ce que l’on fait en 2čme année de BTS IRIS. Rassurer vous, nous allons continuer sur la lancée de l’année précédente. Le tout c’est de ne pas oublier ce que vous avez apprit l’ année derničre. Des le premier jours, nous avons commencé par une petite révision au niveau des classes, de leur déclarations, de leur fonctionnement et sur ce que l’on doit y trouver.
! A premičre vu, je peut vous le dire, pour tout le monde, la reprise ça a été plutôt dure. !
Fini, de se plaindre et rentrons dans le vif du sujet.
Ah oui, une derničre chose, pour ceux qui ont lu mon premier cour, je reprend la męme légende de couleur pour marquer, ce qui ŕ mon goűt, le plus important. Encore merci, de lire mon cour.
Nous avons remarqué que lorsque nous créons des objets d’ une męme classe, chaque objet possčde ses propres attributs.L’ ensemble de ces attributs, nous permettent de définir.
Qu ' est ce qu 'un attribut de classe?
Il peut permettre aux différents objet issu de la classe de partager les informations de telle sorte que lorsqu’ un des objets modifie cette information, que tout le monde soit informé de cette modification. Nous pouvons dire que cette information est mise en commun, représenté par un attribut de la classe et non de l’ objet.
Définition d'un attribut statique
Dans le langage de C++, un attribut de classe corresponds ŕ une variable globale, dont la portée est limité ŕ la classe. Celui- ci est donc déclarer dans la mémoire statique et donc
par conséquence utilisé le préfixe « static ».
Sans oublier de l’ initialiser avec des valeurs correcte.
Cette initialisation doit ętre lancer au moment du lancement du programme comme pour des variables globales.
ATTENTION : Cet attribut aura donc une durée de vie
correspondant ŕ la durée de vie du programme.
Exemple : public static unsigned int taille ;
Cette exemple de code permet de déclarer un attribut de classe TEST.h « statique » du type entier non - signe.
Pour initialiser cette attribut, nous utiliserons le ligne suivante : Unsigned TEST ::taille=10 ;
Si nous avions dut modifier la variable taille, alors tous les objets auraient automatiquement été modifier.
Les méthodes ont la possibilité d'accéder aux attributs statiques comme pour tous les autres attribut. Soit, le constructeur peut tout ŕ fait intervenir et modifier un attribut de classe en sachant toutefois que l'initialisation a déjŕ eu lieu au moment du lancement du programme et qu'il s'agit, dans ce cas lŕ, que d'une évolution.
Méthode statique
Cela s’ applique aussi aux méthodes de la classe, nous imaginons que leur rôle est totalement indépendant d’ un quelconque objet. Une méthode peut aussi ętre déclarer comme « static ».
ATENTION : Une methode « static » n’ a pas de pointeur
« this » et qu’ il est donc absolument interdit d’ accéder ŕ un.
Le mécanisme d'héritage permet de mettre en relation un certain nombre de classes ayant des caractéristiques communes (attributs et comportements) en respectant une certaine filiation.
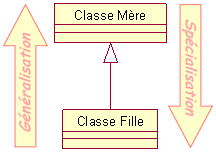
Généralisation
La généralisation se représente par une flčche qui part de la classe « fille » vers la classe « mčre ». Cela corresponds exactement ŕ ce que nous avions avant sans l’ héritage, sauf qu’ avec cette technique, nous évitons toutes les duplications. Toutes les caractéristiques communes n’ apparaissent plus dans chacune des classes « filles », alors qu’ elles sont bien présentes implicitement.
Les héritages peuvent ętre défini sur plusieurs niveau.
Classes abstraites
Déclarer une classe « abstraite » revient ŕ interdir la création d’ objet issu de cette classe. En opposition, ŕ une classe.
Spécialisation
Dans la conception des classes, nous pouvons avoir une démarche inverse de la généralisation, c'est-ŕ-dire, cette fois- ci, de partir plutôt de la classe mčre pour aboutir ensuite aux classes filles.
Le concept d'héritage constitue l'un des fondements de la programmation orientée objet.
Il vous autorise ŕ définir une nouvelle classe, dite dérivée, ŕ partir d'une classe existante dite de base. La classe dérivée héritera donc des potentialités de la classe de base.
Il ne sera pas utile de la recompiler, ni męme de disposer du programme source correspondant (exception faite de sa déclaration).
En outre, l'héritage, n'est pas limité ŕ un seul
niveau : une classe dérivée peut devenir ŕ son tour classe de base pour une autre classe.
Nous voyons apparaître la notion d'héritage comme outil de spécialisation croissante.
Le polymorphisme
Le terme polymorphisme indique qu'une entité peut apparaître suivant plusieurs formes.
Normalement, le principe męme de l'héritage, c'est que lorsque une méthode est décrite sur une classe parente, elle est automatiquement hérité par les classes enfants.
Cette technique s'appelle une redéfinition, c'est-ŕ-dire que dans la classe dérivée, nous allons redéfinir une méthode qui porte le męme nom avec une signature identique
(polymorphisme) que la classe de base.
Une surdéfinition (ou surcharge) permet d'utiliser plusieurs méthodes qui portent le męme nom au sein d'une męme classe, avec une signature différente, pour que le systčme puisse s'y retrouver.
Une redéfinition permet de fournir une nouvelle définition d'une méthode d'une classe ascendante et ainsi de substituer la description qui en été faite. Nous avons également le męme nom que la méthode parente mais surtout avec une signature rigoureusement identique.
Héritage multiple et classe paramétrable
Ainsi une classe peut ętre issue de plusieurs classes, c'est ce qui s'appelle l'héritage multiple.

Ainsi, le cheval est ŕ la fois un quadrupčde et un herbivore. Pour finir, il est bien évidemment possible de proposer l'héritage sur des classes paramétrables.
Dans le chapitre précédent, nous avons évoqués les principes généraux de l'héritage sans tenir compte d'un langage quelconque. Ce chapitre sera donc consacré ŕ l'étude de l'héritage simple codé avec le langage C++.
Déclaration de l 'héritage simple (Classes sans constructeurs)
Pour indiquer une dérivation, il faut utiliser l'opérateur « : » (déjŕ utilisé dans les listes d'initialisation, ici il s'agit d'une liste de dérivation) suivit de nom de la classe de base. Pour un héritage classique, il est nécessaire de faire une dérivation publique.
Ex : class « fille » : public nom_ classe _ mčre
Dans la déclaration dans le .h, nous mettons toujours la classe
« mčre » avant la « fille ».
Utilisation de tous les membres de la classe dérivée
Lorsqu'une classe dérivée hérite d'une classe de base, elle s'approprie de tout le comportement de la classe de base. La classe dérivée récupčre donc l'ensemble des attributs et des méthodes de la classe de base. C'est comme si nous avions une seule classe avec une fusion de tous les attributs et de toutes les méthodes.
Contrôle des accès
Effectivement, l'enfant récupčre tout ce que possčde le parent. Mais attention, il existe quand męme un petit problčme d'accessibilité.
Les statuts des membres d'une classe:
1. privé : Le membre (généralement l'attribut) n'est accessible qu'aux méthodes de la classe (publiques ou privées). De l'extérieur, il n'est pas possible d'atteindre ce membre. Męme sa descendance ne peut pas y accéder directement. Seule l'amitié donne des droits d'accčs privilégiés pour atteindre les attributs privés.
2. public : le membre est cette fois-ci accessible non seulement aux méthodes de la classe et aux fonctions amies, mais également ŕ l'utilisateur de la classe, les enfants compris.
Il existe une rčgle de conception de hiérarchie qui stipule que la classe dérivée ne doit pas avoir besoin de connaître les
détails de l'implémentation de la classe de base. Je pense qu'il est bon d'avoir en tęte cette démarche. Elle correspond ŕ un principe de sécurité maximale.
La classe de base ne possčde pas toujours des méthodes de lecture pour atteindre les attributs. Il serait alors souhaitable d'ętre moins rigoureux et de permettre uniquement ŕ la descendance (l'enfant ou l'enfant de l'enfant) l'accčs ŕ tous les attributs (ou éventuellement une partie) de la classe parente. Il existe un nouveau statut qui propose cette autorisation particuličre. Il s'agit du statut protected .
Les statuts des membres d'une classe
3. protected : Les membres protégés se présentent comme des membres privés pour l'utilisateur de la classe de base, mais ils sont comparables ŕ des membres publics pour la classe dérivée et pour toute la descendance.
Pour l'utilisateur des classes dérivées, les membres protégés continuent ŕ ętre considérés comme des membres privés.
Accès des attributs dans l ' héritage
Nous pensons souvent que pour avoir le maximum de souplesse, il suffit de déclarer protégés tous les attributs de la classe de base. Ainsi les enfants dans toute la hiérarchie peuvent y accéder sans aucune restriction. Toutefois cela peut ętre dangereux puisque un développeur par héritage peut modifier le comportement prévu par la classe de base.
Il ne faut pas que les attributs de la classe de base soient systématiquement protégés. Je pense que par réflexe, il faut d'abord les considérer comme privés, parce qu'il n'est pas toujours nécessaire que les enfants puissent accéder directement ŕ tout ce que font les parents.
Dérivation publique , protégée et privée
Dérivation public
« class nom_deuxieme classe : public nom_premiere classe »
Les membres hérités d'une classe de base publique conservent leurs niveaux d'accčs ŕ l'intérieur de la classe dérivée. C'est le comportement normal prévu.
Dérivation privée
« class nom_deuxieme classe : nom_premiere classe »
Les membres hérités publics et protégés d'une classe de base privée deviennent des membres privés de la classe dérivée.
Cette technique permet d'interdire, aux utilisateurs d'une classe dérivée, l'accčs aux membres publics de sa classe de base. Cela sous-entend que seules les méthodes de la classe dérivée devront ętre utiliser, sinon il faudra redéfinir les méthodes de la classe de base.
Dérivation protected
« class nom_deuxiemeclasse : protected nom_premiereclasse »
Les membres hérités publics et protégés d'une classe de base protégée deviennent des membres protégés de la classe dérivée. Nous retrouvons le męme principe que pour une dérivation privée, la seule différence concerne les enfants éventuels de la classe dérivée, puisque dans ce cas lŕ, les petits enfants peuvent atteindre des membres protégés.
Les membres publics de la classe de base sont accessibles « ŕ tout le monde », c'est-ŕ-dire ŕ la fois aux méthodes, aux fonctions amies de la classe dérivée ainsi qu'aux utilisateurs de la classe dérivée.
Les membres protégés de la classe de base sont accessibles aux méthodes et aux fonctions amies de la classe dérivée, mais pas aux utilisateurs de cette classe dérivée.
Les membres privés de la classe de base sont inaccessibles ŕ la fois aux méthodes ou aux fonctions amies de la classe dérivée et aux utilisateurs de la classe dérivée.
Constructions
Pour une classe, ŕ chaque fois que nous fabriquons un nouvel objet, le souci porte sur sa phase de création. Lorsque nous parlons de l'état de l'objet, il s'agit en fait de la valeur de chacun des attributs. C'est le (ou les) constructeur qui gčre ce genre de problčme au moment de la phase de création.
La classe de base et la classe dérivée possèdent un constructeur par défaut
La création d'un objet se déroule en quatre phases :
1. Allocation mémoire nécessaire pour contenir l'ensemble des attributs que comporte l'objet. Puisqu'il s'agit d'un héritage, l'objet alloue l'espace mémoire pour ses propres attributs ainsi que l'espace mémoire nécessaire aux attributs délivrés par l'héritage. Sinon l'objet ne serait pas complet.
2.Appel du constructeur de la classe dérivée. Ce constructeur est appelé mais pas encore exécuté. En effet, le constructeur de la classe dérivée ne s'occupe uniquement de ce qui fait la spécificité de la classe, c'est-ŕ-dire, initialiser ses propres attributs. Avant d'effectuer cela, il faut ętre sűr que toute la structure générale soit elle-męme bien initialisée. C'est la classe de base qui s'occupe justement de la structure de base et qui gčre l'initialisation de ces propres attributs. Donc, avant l'exécution du constructeur de la classe dérivée, c'est le constructeur de la classe de base qui est appelé.
3.Appel et exécution du constructeur de la classe de base. A moins que la classe de base soit elle-męme une classe dérivée d'une autre classe de base, les instructions qui constituent le corps du constructeur sont exécutées. Au minimum, ces instructions consistent ŕ donner une valeur correcte aux attributs afin que l'objet par la suite n'ait pas de comportement aléatoire. (Si cette classe de base est également une classe dérivée, le systčme appelle d'abord le constructeur de sa classe de base avant l'exécution du constructeur).
4.Exécution du constructeur de la classe dérivée. Puisque la partie générale est bien initialisée, nous pouvons nous occuper de la partie spécifique ŕ la classe dérivée. Les instructions du corps du constructeur sont donc exécutées. Il s'agit également d'initialiser les attributs relatifs ŕ la classe dérivée.

La création d'un objet passe systématiquement par ces quatre phases. Ainsi, nous sommes sűr que l'objet est correctement initialisé. Chaque phase joue son rôle et s'occupe que d'une petite partie, ce qui rend la lecture plus facile. La maintenance s'en trouvera également d'autant plus simplifiée.
La classe de base dispose d'un constructeur par défaut et la
classe dérivée d'un constructeur avec un paramčtre :
Par rapport au scénario précédent, rien ne change vraiment, les quatre phases sont appelées dans le męme ordre.
La classe de base dispose d'un constructeur avec paramčtres :
Lorsque nous disposons d'un constructeur par défaut, l'appel se fait implicitement, c'est-ŕ-dire automatiquement. Lorsque nous avons un constructeur avec arguments, cette fois-ci, il est nécessaire de faire un appel explicite afin d'envoyer les bons arguments au constructeur pour que l'initialisation des attributs correspondent ŕ l'objet désiré.
Du coup, pour la classe dérivée, il est nécessaire de disposer au moins d'un constructeur qui fasse un appel explicite au constructeur de la classe de base en propageant les bons arguments nécessaires aux attributs généraux relatifs ŕ la classe de base.

Quelque soit les situations, nous disposons toujours des quatre męmes phases pour la création de l'objet et toujours dans le męme ordre.
Comportements par défaut et héritage
Constructeur de copie – écriture implicite
Par défaut, le constructeur de copie propose une copie membre ŕ membre. Les attributs de l'objet ŕ créer sont initialisés par rapport aux attributs de l'objet (qui sert de copie) passé en argument. Le męme comportement par défaut reste vrai pour un objet de la classe dérivée.
Un constructeur de classe de base est toujours invoqué avant l'exécution du constructeur de la classe dérivée. Le constructeur de copie est également un constructeur. Il ne fait donc pas exception ŕ cette rčgle, ce qui est logique.
Lorsque le constructeur de copie de la classe dérivée fait référence au constructeur de la classe de base, il passe par la liste d'initialisation.
Constructeur de copie – écriture explicite
Vous savez que le comportement par défaut n'est pas toujours souhaitable, notamment lorsque nous disposons de variables dynamiques au sein męme de la classe. L'héritage n'exclut pas cette problématique, il faut alors gérer la situation.
En fait trois cas peuvent se présenter :
La classe de base possčde au moins une variable dynamique, mais pas la classe dérivée : Dans ce cas, il faut uniquement redéfinir le constructeur de copie de la classe de base. Lorsque nous tenterons de créer un objet de la classe dérivée par copie, l'appel du constructeur de copie de la classe de base se fera implicitement sans aucun problčme particulier.
La classe de base et la classe dérivée possčdent toutes les deux des variables dynamiques : Dans ce cas, il faut redéfinir, bien entendu, les deux constructeurs de copie. Mais attention, lors de la définition du constructeur de copie de la classe dérivée, vous devez impérativement faire un appel explicite au constructeur de copie de la classe de base grâce ŕ la liste d'initialisation. L'appel implicite au constructeur de copie de la classe de base ne marche pas dčs que vous redéfinissez le constructeur de copie de la classe dérivée .
La classe dérivée possčde une variable dynamique, mais pas la classe de base : Vous ętes donc obligé de redéfinir le constructeur de copie de la classe dérivée, ce qui implique que lŕ aussi, vous devez faire un appel explicite au constructeur de copie par défaut ŕ l'aide de la liste d'initialisation.
Opérateur d ' affectation
Lorsque nous utilisons l'affectation par défaut, une copie membre ŕ membre est réalisée. L'ensemble des attributs est bien copié d'un objet vers l'autre, avec d'abord, la copie des attributs relatifs ŕ la classe de base.
Destructeur
Les différentes phases qui constituent la destruction de l'objet s'effectuent dans l'ordre inverse de la construction, c'est- ŕ-dire :
1.Appel du destructeur de la classe dérivée
2.Exécution du destructeur de la classe dérivée.
3.Appel et exécution du destructeur de la classe de base.
4.Libération de la mémoire utilisée par l'objet .
Ces quatre phases existent que le ou les destructeurs soient redéfinis ou pas. Les destructeurs sont ŕ redéfinir dans le cas oů les classes disposent de variables dynamiques.
Redéfinition des méthodes
ATTENTION : Il ne faut pas mélanger la redéfinition et la surdéfinition.
1. Une surdéfinition (ou surcharge) permet d'utiliser plusieurs méthodes qui portent le męme nom au sein d'une męme classe, avec une signature différente, pour que le systčme puisse s'y retrouver.
2. Une redéfinition permet de fournir une nouvelle définition d'une méthode d'une classe ascendante et ainsi de substituer la description qui en été faite. Nous avons également le męme nom que la méthode parente mais surtout avec une signature rigoureusement identique. La redéfinition constitue la base du polymorphisme.
Męme si c'est trčs rarement utilisé, vous pouvez faire un appel explicite ŕ une méthode d'une classe ascendante.
Le terme polymorphisme décrit la caractéristique d'un élément qui peut prendre plusieurs formes, comme l'eau qui se trouve ŕ l'état solide, liquide ou gazeux.
Le polymorphisme, en informatique, désigne un concept de la théorie des types, selon lequel un nom d'objet peut désigner des instances de classes différentes issues d'une męme arborescence. Effectivement, nous avons découvert que les classes issues d'une męme hiérarchie sont compatibles.
Ex : Classe mčre &p = Classe fille( « Lagafe » , « Gaston » ) ;
L'objet p peut aussi bien faire référence ŕ une « Classe mčre » qu'ŕ une « classe fille » ou ŕ tout autre classe créée ultérieurement faisant partie de cette hiérarchie. C'est ce principe lŕ qui offre une grande richesse ŕ la programmation orientée objet.

Ici, nous avons en exemple, une « classe fille » ayant pour noms « Professeur » qui hérite d’une « classe mčre » ayant pour noms « Personne ».
Maintenant, voyons quels sont les principes du polymorphisme.
Les interactions entre objets sont écrites selon les termes des spécifications définies, non pas dans les classes dérivées des objets, mais dans leurs classes de base. Cela permet d'écrire un code détaché des particularités de chaque classe, et d'obtenir des mécanismes suffisamment généraux pour ętre valides dans le futur, quand seront créées de nouvelles classes.
Le terme polymorphisme désigne en fait le polymorphisme du comportement, c'est-ŕ-dire la possibilité de déclencher les méthodes différentes en réponse d'un męme message. Chaque classe dérivée hérite de la spécification des méthodes de ses classes de base, mais a aussi la possibilité de modifier localement le comportement de ces méthodes, afin de mieux prendre en compte les particularités de chacun. C'est le principe męme de la redéfinition des méthodes comme affiche().
Attention, cela parait facile, mais cependant, le
polymorphisme engendre des restrictions en C++.
Par défaut, et contrairement au langage Java, les classes créées dans une hiérarchie dans le langage C++ n'intčgrent pas le polymorphisme. Ici, cela entraîne une modification sur le comportement général de la (ou des) méthodes afin qu'effectivement le polymorphisme soit opérationnel dans notre hiérarchie.
Pour cela, certains critčres doivent ętre respectés :
Pour qu'une méthode soit désignée comme polymorphe, elle devra impérativement ętre virtuelle.
Le polymorphisme est uniquement activé quand un objet de classe dérivée est indirectement adressé via une référence ou un pointeur vers une classe de base.
Dans la suite, nous allons découvrir pourquoi ces deux critčres sont nécessaires.
Il existe un lien de parenté entre les classes d'une męme hiérarchie, nous avons découvert qu'il existe, du coup, une certaine compatibilité. Elle consiste, ici en C++, en un systčme de conversions implicites, mises en oeuvres automatiquement.
Ces conversions sont les suivantes :
D'un objet d'un type dérivé dans un objet d'un type de base
(l'inverse n'est pas possible),
D'un pointeur (ou d'une référence) sur une classe dérivée en
un pointeur (ou une référence) sur une classe de base.
Qu ' est ce qu' une méthode virtuelle ?
Une méthode virtuelle est une méthode particuličre invoquée au moyen d'un pointeur ou d'une référence sur une classe de base ; elle est liée dynamiquement au moment de l'exécution. L'instance invoquée est déterminée par le type de classe de l'objet adressé par le pointeur ou la référence. La résolution d'une méthode virtuelle est transparente ŕ l'utilisateur.
Il suffit de placer le mot réservé « virtual » devant la méthode que nous désirons rendre virtuelle et le tour est joué. Par ailleurs, il n'est pas nécessaire de déclarer virtuelles les méthodes redéfinies dans les classes dérivées, elles le sont automatiquement.
Voici la syntaxe correspondante en C++ : virtual void affiche() ;
Cette instruction indique au compilateur que les éventuels appels de la méthode affiche() doivent utiliser une ligature dynamique et non plus une ligature statique.
Qu ' est ce qui se passe quand le compilateur rencontre cette instruction ?
Lorsque le compilateur rencontre cette instruction, il ne décidera pas de la méthode ŕ appeler.
Il se contentera de mettre en place un dispositif permettant de n'effectuer le choix de la méthode qu'au moment de l'exécution de cette instruction, ce choix étant basé sur le type exact de l'objet ayant effectué l'appel.
Plusieurs exécutions de cette męme instruction pouvant appeler des méthodes différentes.
Conclusion : Nous voyons que nous pouvons intégrer le polymorphisme vraiment trčs simplement. Il suffit de déclarer la ou les méthodes voulues de la classe de base comme virtuelles. La seule difficulté finalement, se situe au moment de la phase de conception durant l'élaboration des diagrammes UML. C'est effectivement ŕ ce moment lŕ qu'il faut décider si une hiérarchie de classes propose le polymorphisme ou pas. Dans l'affirmative, il est en effet souvent nécessaire de rajouter de nouvelles méthodes dans la classe ancętre, alors que ce n'était pas spécialement prévu au départ.
En voyant cette simplicité, nous pourrions nous dire que nous n'avons pas besoin de nous poser autant de questions. Nous pouvons systématiquement spécifier toutes les méthodes comme virtuelles, puisque nous rajoutons un seul mot sur chacune des méthodes de la classe de base. L'étude suivante va nous montrer que ce n'est pas aussi simple.
Quel est en réalité le mécanisme qui tourne derrière tout cela ?
Nous venons de voir que le polymorphisme est trčs simple ŕ implémenter dans le langage C++.
Nous pouvons nous passer de toutes autres connaissances subsidiaires. Or, cependant pour les programmeurs avertis, il est peut ętre intéressant d'avoir une compréhension plus fine du mécanisme interne, en prenant connaissance de l'implantation de la ligature dynamique.
D'une maničre générale, lorsqu'une classe comporte au moins une méthode virtuelle, le compilateur lui associe une table contenant les adresses des méthodes virtuelles correspondantes.
D'autre part, tout objet d'une classe comportant au moins une méthode virtuelle se voit attribuer par le compilateur, outre l'emplacement mémoire nécessaire ŕ ses attributs, un emplacement supplémentaire de type pointeur, contenant l'adresse de la table associée ŕ sa classe.
Voyons maintenant , quelles sont les propriétés d ' une méthode virtuelle !
Dans ce chapitre, nous allons faire un certain nombre de remarques afin que les méthodes virtuelles soient correctement implémentées.
Les méthodes virtuelles doivent impérativement existées pour qu'elles puissent ętre adressées ŕ l'aide de la table correspondante. Elles sont donc nécessairement non inline (si vous la déclarez inline, le compilateur fabrique une véritable méthode).
Le mot virtual se place uniquement dans la déclaration de la classe. Lorsque vous définissez la méthode ŕ l'extérieur de la classe, vous ne devez plus re-spécifier le mot virtual devant la signature de la méthode.
La redéfinition d'une méthode virtuelle dans une classe dérivée doit réaliser une adéquation parfaite (nom, signature, et type de retour) avec la méthode virtuelle déclarée dans la classe de base. Il n'est pas nécessaire de re-spécifier le mot virtual. Si la re-déclaration dans la classe dérivée ne réalise pas une adéquation parfaite, la méthode n'est pas gérée comme une méthode virtuelle de la classe dérivée. Dans ce cas lŕ, il s'agira tout simplement d'une surdéfinition.
Il n'est pas obligatoire que toutes les classes dérivées redéfinissent impérativement toutes les méthodes virtuelles données par la classe de base. C'est notamment le cas lorsque la méthode héritée de la classe de base fait déjŕ tout ce qu'il faut. Par contre, rien n'empęche ŕ une classe ultérieurement dérivée de ces classes dérivées de proposer, elle, la redéfinition de la méthode virtuelle, męme si son proche parent ne l'a pas fait.
Lorsque nous avons une redéfinition des destructeurs dans une hiérarchie de classe qui comporte des méthodes virtuelles, il est généralement préférable que les destructeurs fassent également partie des tables des adresses des méthodes virtuelles.
En effet, lorsque nous réalisons un delete sur un pointeur d'une classe de base, le bon destructeur est alors pris en compte. Vous obtenez ce comportement en déclarant virtuel le destructeur de la classe de base.

Lorsque qu'une méthode virtuelle est invoquée ŕ l'intérieur d'un des constructeurs de la hiérarchie, c'est toujours la méthode virtuelle de la classe de base qui est sollicité.
En effet, puisque nous sommes en phase de création, les tables des adresses des méthodes virtuelles n'existent pas encore. Nous ne pouvons donc pas intégrer le polymorphisme sur un constructeur, il faut que l'objet soit d'abord créé. Du coup, un constructeur ne peut jamais ętre virtuel.
Comment est mise en oeuvre une classe abstraite ?
Contrairement aux autres langages, comme le JAVA par exemple, il n’est pas possible d’indiquer directement qu’une classe est abstraite.
En réalité, pour que des méthodes soient réellement désignées comme abstraites ou bien indiquer qu'elles ne font vraiment rien, elles doivent ętre explicitement initialisées ŕ 0. Donc ŕ la suite de la signature de la méthode, vous devez placer « = 0 ; ». Ces méthodes sont appelées, dans le langage C++, des méthodes virtuelles pures.
Lorsque vous héritez d'une telle classe, vous devez impérativement, si vous désirez que votre classe devienne concrčte, redéfinir toutes les méthodes virtuelles pures. Si cette condition n'est pas réalisée, la classe dérivée est elle-męme une classe abstraite.
Finalement, dans le langage C++, une classe est abstraite lorsqu'elle dispose d'au moins une méthode abstraite, c'est-ŕ-dire une méthode virtuelle pure.
Une fois, qu'une classe est définie abstraite, il n'est plus possible de créer un objet relatif ŕ cette classe. Une erreur de compilation se produit si vous tentez l'expérience.
Q u ' est ce qu ' une classe générique ?
La généricité permet d'avoir des fonctions et des classes paramétrables, c'est-ŕ-dire que, au moment oů nous en avons besoin, nous précisons le type ŕ utiliser pour ladite fonction ou ladite classe. C'est le type qui est paramétrable. Ce concept nous permettra d'avoir des écritures plus concises et ainsi d'éviter de nombreuses surdéfinitions. La généricité est souvent appelée « template » ( patron ± évocation de la haute couture), ou également « modčle ». Implémentation et utilisation d¶une classe générique :
Implémentation et utilisation d ' une classe générique

Q u ' est ce qui se passe au niveau de la compilation ?

Le schéma ci-dessus, nous montre clairement, qu’est ce qui se passe lors de l’ utilisation des « templates » aprčs compilation du programme principal faite.
Grâce aux « templates », nous pouvons créées et adaptées ŕ volonté des méthodes utilisable ŕ tout moment. C’est le moyen, le plus efficace pour concevoir une boite ŕ outils. De cette façon, l’utilisateur de la méthode avec un type primaire désiré pourra utilisé votre méthode sans aucun problčme. La classe contenant des « templates » s’appelle en langage de programmeur « un modele ».
Le modčle nous sert en fait ŕ composer, une fois pour toute, les lignes de codes nécessaires ŕ l'élaboration de fonctions surdéfinies et c'est le compilateur qui finalement travaille pour nous. Cela nous évite d'écrire des lignes de codes identiques.
Fonctions génériques
Pouvons - nous mettre le mot « inline » avec les fonctions génériques ?
Nous pouvons modéliser n'importe quel type de fonction et le fait qu'elle puisse ętre « inline » ne change absolument rien.
Pouvons - nous surdéfinir une fonction générique ?
L'avantage de ces modčles c'est d'écrire trčs peu de ligne de codes.
Nous pouvons donc faire coexister des fonctions génériques avec des fonctions classiques. Le tout, c'est de proposer des signatures différentes pour que le compilateur soit ŕ męme de comprendre le souhait du programmeur et donc de résoudre la surdéfinition.
Pouvons - nous rendre une fonction standard en une fonction générique ?

Classes génériques - Conception
Les classes aussi peuvent ętre génériques.
La syntaxe demeure identique ŕ l'écriture des fonctions génériques. Partout oů le type « int » ou bien tout autres types primaire sont utilisés, vous le remplacez par le paramčtre « Type » puisque c'est lui qui est défini dans le modčle.
Mise ŕ part l'écriture de la partie paramétrable, les classes génériques demandent trčs peu d'investissement supplémentaire. Il ne faut pas hésiter ŕ utiliser cette technique.
Classes génériques – Utilisation
Il existe toutefois une petite différence dans l'utilisation des classes génériques par rapport aux fonctions génériques.
Le compilateur, au moment de l'appel d'une fonction générique, contrôle la signature proposée et détermine le type demandé pour effectivement fabriquer la fonction avec le type désiré. Sans spécification supplémentaire, le compilateur arrive ŕ connaître le type demandé.
Dans le cas d'un objet, c'est différent. Lorsque nous déclarons cet objet, le type de certains attributs n'apparaît pas au moment de la déclaration puisque seul le nom de l'objet est visible.
En conséquence, il est nécessaire, durant la création d'indiquer le ou les types voulus. La syntaxe est simple d'utilisation. Aprčs le nom de la classe, vous devez préciser le type voulu entre « <> ».
Le nom de votre type devient alors l'argument de votre classe générique. Du coup, la syntaxe de votre code est trčs lisible, en ce sens que nous voyons bien qu'il s'agit, par exemple, d'un tableau d'entiers ou d'un tableau de complexes.
Classes génériques – Définition des méthodes

D'habitude, lorsque nous développons des classes, nous plaçons la déclaration de la classe dans un fichier en-tęte alors que la définition de ses méthodes se trouve dans le fichier source correspondant qui porte le męme nom, mais dont l'extension de fichier est « *.cpp ».
Dans le cas d'une classe générique, c'est différent. N'oubliez pas qu'il s'agit d'un prototype (d'un patron) qui servira ŕ la fabrication (réelle) de plusieurs classes de types différents. Dans ce contexte, la déclaration de la classe ainsi que la définition des méthodes doivent se trouver entičrement dans le fichier en-tęte.
En effet, tout ce qui est générique est utilisé uniquement par le « préprocesseur » du compilateur, et n'oubliez pas que cette phase particuličre de la compilation propose de transformer un texte par un autre. Ce n'est que lorsque le texte a été mis en place que la compilation réelle s'effectue.
En revenant sur notre exemple, ŕ l'utilisation, nous avons besoin d'avoir d'une part un tableau d'entiers et d'autre par un tableau de réels. Bien que le code interne soit identique, il existe tout de męme des différences. Nous ne traitons pas des réels comme des entiers. Il faut donc qu'il y ait, par exemple, un constructeur pour un tableau d'entier et un constructeur pour un tableau de réel puisque la réservation mémoire dynamique est totalement différente. Les réels prennent plus de place en mémoire. Pour un tableau de complexe, c'est encore pire.
Finalement, les méthodes sont également paramétrées. Dans ce contexte, ŕ la définition de chaque méthode, vous devez impérativement utiliser la syntaxe complčte des « templates ».
Classes génériques – Paramètre non type
Nous avons vu qu'il existait deux types de paramčtres pour les fonctions et les classes génériques : les paramčtres de type, et les paramčtres non type.

Dans le cas des classes génériques, le paramčtre « non type » peut s'avérer particuličrement utile, notamment pour implémenter un tableau de type quelconque en spécifiant, dčs le départ, la dimension du tableau, et c'est ce dernier élément qui servira de paramčtre non type. En effet, dans ce cas lŕ, le paramčtre attend une valeur entičre non signée. Il ne s'agit en aucun cas de proposer un type mais bien une valeur.

En prenant un paramčtre non type pour spécifier la dimension, le code de la classe devient extręmement simple. En effet, comme la dimension est connue en moment de la création de la classe, il est possible de mettre comme attribut un tableau et non plus un pointeur vers une variable dynamique. Du coup, nous n'avons plus besoin de redéfinir tous les comportements par défaut. Il suffit de redéfinir l'opérateur de crochets « [ ] ».

Introduction
Le langage C++ est un langage intéressant puisqu'il offre avec une grande souplesse d'écriture.
Par rapport au langage C dont il hérite, il propose beaucoup plus de choses comme, bien entendu, toute la philosophie objet, mais également la possibilité de redéfinir les opérateurs ainsi que la possibilité de fabriquer des modčles.
Malheureusement, il conserve aussi quelques tares issues de son prédécesseur, notamment les tableaux et les chaînes de caractčres.
N'oubliez pas que les tableaux ne sont pas de véritables tableaux, mais des pointeurs vers des mémoires consécutives. Męme si elle traite de caractčres, la chaîne n'est pas mieux lotie puisqu'elle est également considérée comme un tableau (et donc comme un pointeur).
Les ingénieurs de Hewlett Packard ont développé beaucoup d'autres classes comme les nombres complexes, les nombres binaires, des classes conteneurs comme les listes, les piles, les ensembles, etc. Tous ces éléments sont rassemblés dans une bibliothčque standard et sont construits sous forme de modčles. Cette librairie s'appelle STL (Standard Template Library).
Quels sont les contenus disponible dans la STL ?
Les conteneurs séquentiel :
Il est trčs fréquent d'avoir besoin de stocker dans une męme entité mémoire un ensemble d'objets de męme type. En plus, il peut ętre intéressant d'utiliser un systčme qui fonctionne quelque soit l'objet que nous développons. Les conteneurs séquentiels permettent effectivement de stocker des objets en séquence, c'est-ŕ-dire les uns ŕ la suite des autres, ce qui permettra ensuite de parcourir le conteneur dans un ordre particulier.
Il existe plusieurs conteneurs séquentiels :
vector : cette classe est un vecteur qui représente un tableau de haut niveau (les cases sont consécutives). Avec cette classe, il est possible d'atteindre n'importe quelle élément du tableau facilement grâce ŕ l'indexation « [ ] ». Nous pouvons insérer de nouveaux éléments, en supprimer, etc.
list : cette classe implémente une liste doublement chaînée. Avec cette classe, il est plus facile de supprimer un élément particulier par rapport au vecteur (en effet pour un vecteur, si nous supprimons une case, il est nécessaire de décaler les cases suivantes vers le bas). Par contre, cette liste utilise systématiquement deux pointeurs pour parcourir la séquence ce qui prend plus de place en mémoire.
deque : cette classe est trčs peu utilisée et offre le męme comportement mais plus spécialisé que la classe vecteur. Sa spécialisation consiste ŕ pouvoir facilement ajouter ou retirer le premier élément. Cette classe est une abstraction d'une file pour laquelle le premier élément est retiré chaque fois.
Existe t – i l des adaptateurs pour les conteneurs séquentiels ?
La bibliothčque standard dispose de trois patrons particuliers qui s'ajoutent aux conteneurs séquentiels en modifiant leurs comportements classiques.
Généralement, il s'agit d'une restriction et d'une adaptation ŕ des fonctionnalités données :
stack : ce patron est destiné ŕ la gestion des piles LIFO (Last In, First Out).
queue : ce patron est destiné ŕ la gestion des piles de type FIFO (First In, First Out).
priority_queue : un tel conteneur ressemble ŕ une file d'attente, dans laquelle on introduit toujours des éléments en fin.
Les conteneurs associatifs
Les éléments d'un conteneur associatif ne sont plus placés dans un ordre particulier. Pour retrouver une entité, nous ferons appel dans ce cas lŕ ŕ une clé qui nous orientera vers la valeur recherchée.
map : ce conteneur représente une correspondance entre deux entités sous la forme d'une paire clé/valeur , la clé étant utilisée pour la recherche et la valeur contenant les données que l'on souhaite utiliser. Par exemple, un répertoire téléphonique.
multimap : ce conteneur représente une multicorrespondance, il peut donc stocker plusieurs occurrences d'une męme clé.
set : ce conteneur représente la théorie des ensembles et contient une valeur de clé unique et supporte les requętes concernant sa présence ou non. En effet, grâce ŕ ce conteneur, nous pourrons indiquer si un élément fait parti de l'ensemble ou pas.
multiset : représente également la théorie des ensembles avec en plus la possibilité de comptabiliser le nombre de fois qu'un męme élément apparaît dans l'ensemble. Ce conteneur autorise donc la présence de plusieurs éléments identiques, ce qui n'est pas le cas pour le conteneur set .
Les algorithmes génériques
De męme que la STL est composée de classes génériques, elle est également composée de fonctions génériques qui fournissent des opérations supplémentaires bien utiles sur les différents conteneurs étudiés précédemment.
Ces fonctions permettent d'effectuer un certain nombre de traitements différents, comme des insertions, des copies, des recherches, etc., dans une suite d'éléments d'un des conteneurs utilisé.
L'intéręt de ces fonctions génériques, que l'on appelle aussi algorithmes génériques, c'est qu'elles sont opérationnelles pour tous les types de conteneur, comme vector, list, map, etc.
La liste ci-dessous vous donnera une idée de quelques fonctions génériques intéressantes :
copy : copie d'une séquence dans une autre,
count : comptabilise le nombre d'élément présent dans une suite,
generate : génération de valeurs par une fonction,
find : recherche d'une valeur particuličre,
max_element : recherche du maximum,
min_element : recherche du minimum,
replace : remplacement de valeurs,
rotate : permutation de valeurs,
remove : suppression de valeurs,
unique : suppression de doublons,
sort : tri d'une séquence,
merge : fusion de deux conteneurs.
reverse : inverse l'ordre des éléments dans un conteneur.
Quelles sont les classes les plus utilisées en développement d ' application ?
Nous avons commencé cette étude en indiquant que le langage C++ ne possédait pas certains éléments qui sont indispensables ŕ la programmation de haut niveau, comme les chaînes de caractčres.
Par ailleurs, dans nos différentes études, nous avons en oeuvre de toute pičce une classe qui représente les nombres complexes.
Il faut savoir qu'une telle classe fait partie de cette bibliothčque.
Voici une liste non exhaustive de classes qui me paraissent intéressante :
string : cette classe représente une chaîne de caractčres et possčde beaucoup de méthodes qui permettent tous les traitements possibles sur ses caractčres. C’est la classe que l’ on utilisera des que c’est possible.
complex : cette classe représente les nombres complexes.
bitset : cette classe représente les nombres binaires ou plus précisément un ensemble de bits et possčdent des méthodes associées ŕ leurs traitements. Elle permet de faire des traitements divers sur les chiffres binaire, hexa, décimaux,etc.
Vector, list, map.
Maintenant, le mieux pour nous est de voir comment marche ces différentes classes tellement pratique.
La classe « string »
Un objet de type « string » contient a un instant donné, une suite formée d'un nombre quelconque de caractčres.
Sa taille peut évoluer dynamiquement au fil de l'exécution du programme.
En fait, cette chaîne réserve un bloc mémoire suffisant pour stocker un certain nombre de caractčres.
Si la chaîne désirée est plus grand que cette zone réservée, la classe augmente automatiquement ce bloc en proposant une nouvelle allocation mémoire et en prenant la précaution d'avoir un bloc plus grand que nécessaire afin de répondre rapidement ŕ une petite augmentation de la taille de la chaîne.
La notion de caractčre de fin de chaîne n'existe plus pour cette classe, et ce caractčre de code nul peut apparaître au sein de la chaîne, éventuellement ŕ plusieurs reprises.
Comment peut - on utiliser cette fameuse classes ?
Pour utiliser cette classe, nous devons ne pas oublier de faire une directive (une inclusion) de compilation tout au début du programme.
Cette inclusion est : #include <String>.
Mais, aussi, nous devons utiliser l’espace de nom « standard » en inscrivant « using namespace std ; »
Description des différentes méthodes incluent dans la classe « string »
1. append : ajoute une chaîne, ŕ la fin d'une autre. Il s'agit d'une concaténation qui peut ętre également traitée par l'opérateur += .
2. assign : affecte ŕ l'objet une nouvelle chaîne de caractčres.
3. at : permet de lire ou de récupérer un caractčre ŕ la position indiquée. La premičre position est 0. Il est nécessaire de donner une position compatible et inférieure ŕ la taille de la chaîne sinon une exception est levée. Cette méthode est similaire ŕ la redéfinition de l'opérateur « [ ] ».
4. capacity : retourne la dimension du bloc mémoire réservé. Cette méthode fournit donc le nombre maximal de caractčres qu'on pourra introduire, sans qu'il soit besoin de procéder ŕ une nouvelle allocation mémoire. Les méthodes reserve et resize pouront ętre utilisée pour agir directement sur la capacité de ce bloc mémoire. La valeur retournée est toujours plus grande ou égale ŕ la valeur que retourne la méthode size.
5. clear : vide entičrement la chaîne de caractčres.
6. compare : cette méthode gčre l'ordre alphabétique et retourne une valeur numérique négative ou positive suivant le placement de la chaîne par rapport ŕ celle qui est passée en argument. Une valeur négative indique que la chaîne se trouve avant celle qui est passée en argument. Une valeur positive dans le cas contraire, et une valeur nulle dans le cas oů les deux chaînes sont rigoureusement identiques. La plupart du temps, il sera préférable d'utiliser les opérateurs relationnels « <, <=, ==, !=, >, >= » pour gérer ce genre de problčme.
7. c_str : cette méthode permet de passer d'une chaîne de type « string » vers une chaîne classique du C++ (const char *).
8. empty : retourne true si la chaîne est vide (sans aucun caractčre), sinon retourne false .
9. erase : efface une partie de la chaîne ou un caractčre spécifié en argument.
10. find, rfind, find_first_of, find_last_of, find_first_not_of, find_last_not_of : effectuent des recherches sur une partie de la chaîne ou sur un caractčre spécifié en argument.
11. insert : permet d'insérer une autre chaîne ou bien un ou plusieurs caractčres donnés.
12. length : retourne la longueur de la chaîne de caractčres. Similaire ŕ la méthode size.
13. replace : remplace une partie de chaîne.
14. reserve : réserve un bloc mémoire dont la taille est fixé par l'argument. Cette méthode doit ętre rarement utilisé, juste dans le cas oů la performance en terme de rapidité est primordiale ou alors, éventuellement, dans le cas oů nous sommes trčs limité dans la capacité de la mémoire.
15. resize : donne une nouvelle dimension ŕ votre chaîne de caractčres. Attention ! ŕ utiliser avec beaucoup de précaution.
16. size : retourne la longueur d'une chaîne de caractčres. Similaire ŕ length.
17. substr : retourne une partie de chaîne.
18. swap : assure la permutation de deux chaînes de caractčres.
19. begin et end : ces opérations retournent des itérateurs au début et ŕ la fin de la chaîne. Un itérateur est une abstraction d'un pointeur de classe générique, fourni par la bibliothčque standard. Ce sujet sera traité ultérieurement lorsque nous utiliserons la classe « vector ».
20. getline(istream &, string, char délimiteur) : cette fonction est trčs utile lorsque nous devons saisir tout un texte ŕ partir du clavier. En effet, lorsque nous réalisons une saisie classique, nous sommes obligé de le faire ligne par ligne. Cette fonction permet justement de saisir un texte qui comporte plusieurs lignes. Il est alors nécessaire de choisir un caractčre (délimiteur) qui servira de caractčre de fin de texte.
A la suite de tout cela, vous devez vous en douter qu’il faut redéfinir certains opérateurs pour nous permettre par la suite d’avoir une écriture plus simple.
Attention, certains opérateurs disposent de méthodes équivalente.
= : affecte une chaîne ŕ une autre. Cet opérateur est équivalent ŕ la méthode assign.
[ ] : joue le męme rôle que pour une chaîne de caractčres classique du C++. Est similaire ŕ la méthode at.
+= : ajoute une chaîne ŕ la fin d'une autre. Cet opérateur joue le męme rôle que la méthode append.
+ : cet opérateur assure la concaténation de deux chaînes de caractčres pour former une troisičme chaîne.
==, !=, <, >, <=, >= : ces opérateurs renvoient true ou false suivant la comparaison qui est faite sur deux chaînes de caractčres. Les différentes comparaisons évaluent en fait l'ordre alphabétique.
>>,<< : Il est aussi possible d' afficher ou de saisir des chaînes de caractčres de type « string » en utilisant la classe « iostream ».
Pouvons- nous faire de la concaténation de deux « string » ?
Oui, c’est tout a fait possible grâce ŕ l'opérateur « + » qui ŕ été redéfini pour permettre la concaténation. Cependant, il faut respecter ces deux rčgles qui suivent pour que cela marche bien.
de deux objets de type «string»,
d'un objet de type «string» avec une chaîne usuelle (char *) ou avec un caractčre, et ceci dans n'importe quel ordre.
De męme pour l'opérateur « += » a également été redéfini pour la concaténation.
Pouvons nous , ou bien avons - nous la possibilitée de rechercher une chaîne de caractères parmi un texte ?
Oui, cela est tout a fait possible, car dans cette classe se trouve des méthodes qui permettent de trouver ce que l'on cherche.
Ces méthodes permettent de retrouver la premičre ou la derničre occurrence d'une chaîne ou d'un caractčre donnés, d'un caractčre appartenant ŕ une suite de caractčres donnés, d'un caractčre n'appartenant pas ŕ une suite de caractčres donnés. Ces méthodes retournent l'indice correspondant au premier caractčre concerné.
Si la recherche n'aboutit pas, on obtient une valeur d'indice en dehors des limites permises pour la chaîne, ce qui rend quelque peu difficile l'examen de sa valeur.
Heureusement, dans la classe string, il existe un attribut constant public et statique appelé npos (qui veut dire : no position) qui généralement est initialisé ŕ la valeur -1. Lorsque vous utilisez une des méthodes de recherche, il serait souhaitable de tester la valeur retournée avec cette constante statique npos de string afin de savoir si votre recherche a aboutie.
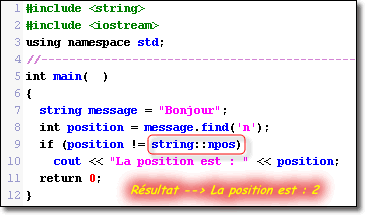
Ci-dessus, nous pouvons voir qu’il existe des méthode spécialement faite pour cela (par exemple le numéro 10).
Passons en détail ces méthodes de recherche.
Méthode « find () »
La méthode find permet de rechercher, dans une chaîne donnée, la premičre occurrence :
1. d'une autre chaîne (on parle alors de sous-chaîne) fournie en argument,
2. d'une autre chaîne usuelle, soit d'un caractčre donné.
Méthode « rfind () »
De maničre semblable, la méthode rfind permet de rechercher la derničre occurrence d'une autre chaîne ou d'un caractčre.
Autres méthodes de recherche
La méthode find_first_of recherche la premičre occurrence de l'un des caractčres d'une autre chaîne (string ou usuelle), tandis que find_last_of en recherche la derničre occurrence.
La méthode find_first_not_of recherche la premičre occurrence d'un caractčre n'appartenant pas ŕ une autre chaîne, tandis que find_last_not_of en recherche la derničre.
Pour les autres méthodes, telle que l' insertion, la suppression, le remplacement, je pense que vous avez compris.
Sinon, veuillez me contacter. Merci.
La Classe « bitset »
Dans la STL, une telle classe existe, elle est représentée par la classe générique « bitset » et permet également de manipuler efficacement des suites de bits dont la taille est spécifiée en paramčtre du modčle. L'affectation n'est donc possible qu'entre suites de męme taille.
Comment ce passe la phase construction ?
Il existe quatre constructeurs :
1. sans argument : on obtient une suite de bits nuls,
2. ŕ partir d'un unsigned long : on obtient la suite correspondant au motif binaire contenu dans l'argument,
3. ŕ partir d'une chaîne de caractčres « string » (attention toutefois, il s'agit d'une construction de type « explicit »),
4. la construction par copie est implémentée et donc possible.

Ici , que signifie le terme « explicit » ?
explicit : Par défaut, les constructeurs permettent de réaliser des conversions implicites lorsque cela est nécessaire. Il peut arriver que dans certaines situations cette conversion automatique soit gęnante. Nous pouvons alors bloquer le comportement par défaut du constructeur en demandant que l'argument passer au constructeur au moment de la création de l'objet soit rigoureusement du type attendu. Pour offrir cette alternative, il est nécessaire de préfixer le constructeur du mot réservé « explicit ». Lorsque nous avons un constructeur avec un seul paramčtre, il est possible d'utiliser l'opérateur « = ». Si vous déclarez un constructeur de type « explicit », cette opportunité n'est plus possible (« = » --> création implicite de l'objet). Il est alors nécessaire d'utiliser systématiquement les parenthčses.
Faut – il redéfinir les opérateurs pour effectuer une opération binaire en utilisant cette classe ?
Nous disposons des opérateurs classiques de manipulation globale des bits « &, |, ~, ^, <<, >>, &=, |=, ~=, ^=, <<=, >>=, ==, != » qui fonctionnent de la męme façon que les męmes opérateurs appliqués ŕ des entiers.
Nous pouvons accéder ŕ un bit de la suite ŕ l'aide de l'opérateur « [ ] » ; il déclenche une exception « out_of_range » si son opérande n'est pas dans les limites permises (les exceptions seront traitées ultérieurement).
>>, << : il est également possible d'afficher ou de saisir des « bitset » en utilisant les opérateurs des classes « iostream ».
Quelles sont les méthodes qui se trouvent dans la classe « Bitset » ?
La classe « bitset » dispose de méthodes supplémentaires qui, associées ŕ l'opérateur « [ ] », permettent de satisfaire les programmeurs lorsqu'il s'agit de manipuler efficacement une information binaire.
any( ) : existe-t-il au moins un bit dans le nombre binaire qui est ŕ 1 ?
none( ) : inverse de la précédente, tous les bits sont-ils ŕ 0 ?
count( ) : détermine le nombre de bits mis ŕ 1.
size( ) : indique la capacité (nombre de bits) du nombre binaire.
set( ) : tous les bits du nombre sont mis ŕ 1.
set(position) : le bit désigné par position est mis ŕ 1.
reset( ) : tous les bits sont mis ŕ 0.
reset(position) : Le bit désigné par position est mis ŕ 0.
flip( ) : inverse tous les bits du nombre.
flip(position) : inverse le bit désigné par position.
test(position) : teste si le bit désigné par position est ŕ 1. La méthode renvoie true, et false suivant le résultat du test.
to_string( ) : retourne la valeur binaire sous forme de « string ».
to_ulong( ) : retourne la valeur binaire sous forme de valeur entičre de type « unsigned long ».
Utilisation de la classe « bitset »
Cette inclusion doit ętre faite pour l’utilisation de celle-ci :
#include <bitset>;
La classe « vector »
La classe vector sera presque systématiquement utilisée pour implémenter les tableaux. Notre premičre approche sera justement dans ce sens.
Toutefois, la classe vector représente bien plus que cela. Elle fait également partie de l'ensemble des conteneurs, et notamment des conteneurs de type séquentiel.
Notre deuxičme approche sera donc liée ŕ cette notion, et nous en profiterons pour généraliser le concept de conteneur.
Pour finir, nous utiliserons les algorithmes génériques afin de résoudre un certain nombre de critčres qui ne sont pas spécialement intégrés dans cette classe.
ATTENTION : Ne pas oublier de rajouter la directive de compilation correspondante.
Cette inclusion est : #include <vector>.
La classe vector remplace aisément les tableaux classiques en offrant des manipulations simples et intuitives. Ainsi, il est possible de construire des tableaux de type quelconque, en indiquant le nombre de cases requis. Il est également possible d'initialiser un tableau avec une valeur particuličre pour toutes les cases du tableau ou męme de spécifier une valeur d'initialisation différente pour chacune des cases du tableau.
Un certain nombre d'opérations peuvent ętre réalisées simplement, comme :
= : l'affectation est possible entre deux tableaux de męme type (Attention, il faut aussi qu'ils comportent le męme nombre de cases).
[] : l'opérateur d'indexation ŕ bien évidemment été redéfini pour supporter le comportement classique d'un tableau, puisque cet opérateur ŕ été spécialement créé pour les tableaux.
==, !=, <, <=, >, >= : Il est de plus possible de comparer le contenu de deux tableaux entre eux en utilisant les opérateurs classiques de comparaison.
Vu la simplicité d'utilisation, il est impératif d'utiliser cette classe pour implémenter les tableaux.
La classe « vector » engendre des conteneurs vecteurs de différents types.
Quelles sont les propriétées communes au conteneur , vector , list, deque ?
J'ai déjŕ donné une brčve description de ces trois types de conteneurs, je ne vais donc pas m'y étendre. Ce qui nous intéresse, ici, c'est de voir le comportement commun qui donne une certaine homogénéité dans la STL.
Directive de compilation « type def »
Le compilateur offre des mécanismes fort intéressants pour simplifier le travail du programmeur. Le préprocesseur, grâce ŕ la directive typedef permet de donner un synonyme ŕ un type de donnée standard ou défini par l'utilisateur.
C'est comme si nous définissions un nouveau type alors qu'il s'agit en fait d'un simple changement de texte durant la phase de précompilation.
Une définition par typedef commence avec le mot clé typedef, suivi du type de donnée et ensuite de l'identificateur.
L'identificateur, ou le nom typedef, n'introduit pas un nouveau type mais plutôt un synonyme pour le type de donnée existant. Un nom typedef peut apparaître n'importe oů dans le programme, lŕ ou un nom de type peut apparaître.

Dans tous les cas, pour parcourir un conteneur, nous serons amené ŕ utiliser des itérateurs.
Q u ' est ce qu ' un itérateur ?
Un itérateur fournit un moyen général pour accéder successivement ŕ chaque élément ŕ l'intérieur de n'importe quel type de conteneur.
Un itérateur correspond ŕ un pointeur qui, comme tous les pointeurs, permet d'utiliser l'incrémentation ou la décrémentation.
! Tout cela est bien joli, mais voyons maintenant ce que c' est le sens direct et le sens inverse. !
Sens direct de parcours d ' un conteneur
Grâce ŕ un itérateur, nous pouvons naviguer avec une facilitée déconcertante. Pour cela, il vous ait possible d' incrémenter cet itérateur. Mais aussi, de le dé-référencer, pour obtenir la valeur correspondante au chiffre itérée et donc ŕ la valeur de l' élément de la séquence.
Chaque type de conteneur fournit deux méthodes :
begin() : retourne un itérateur qui adresse le premier élément du conteneur,
end() : retourne un itérateur qui adresse un élément aprčs le dernier élément du conteneur.
Exemple de fonctionnement d ' un itérateur pour le sens direct

Sens inverse de parcours d ' un conteneur

Et oui, il est également possible de parcourir un conteneur en sens inverse.
Attention, il faut pouvoir démarrer sur le dernier élément, ce que ne fait pas la méthode end() , puisqu'elle se trouve aprčs le dernier élément.
D'autres méthodes ont donc été implémentées pour résoudre cette situation :
rbegin() : retourne un itérateur qui adresse le dernier élément du conteneur,
rend() : retourne un itérateur qui adresse un élément juste avant le premier élément du conteneur.
Comment déclarer un itérateur ?
L'avantage de ce mécanisme, c'est qu'il fonctionne quelque soit le type de conteneur utiliser alors que la structure interne de chacun d'entre eux peut ętre totalement différente.
Il faut savoir que, pour les vecteurs, les éléments sont stockés sur des cases mémoires contiguës, alors que pour la liste ce n'est pas du tout le cas. La seule solution pour résoudre ces difficultés est de prendre le mécanisme des pointeurs.
Il faut bien comprendre également que ces différents conteneurs stockent des données de type quelconque ( int , double , string , etc.).
Ceci dit pour réaliser ces différents parcours, il est bien évidemment nécessaire de déclarer la variable qui représente l'itérateur. Souvenez-vous que, pour que l'incrémentation d'un pointeur se fasse dans les bonnes conditions, il est impératif de connaître le type de l'élément faisant parti du conteneur.
Illustration :

La solution retenue a donc été de proposer un attribut public, présent sur tous les conteneurs, qui s'appelle iterator .
Cet attribut est en fait un pointeur sur le type passé en paramčtre du modčle de la classe conteneur. Cette démarche est possible grâce ŕ la directive de compilation typedef. Cette astuce est géniale malgré la petite lourdeur de la déclaration. Vous avez ci-dessous un exemple d'un parcours dans le sens direct d'une liste d'entiers.
Il existe également un deuxičme itérateur spécialisé pour parcourir le conteneur en sens inverse, qui s'appelle reverse_iterator.
Par ailleurs, bien que rarement utilisé, la décrémentation peut ętre utilisée par les deux types d'itérateurs.
Illustration :
SENS DIRECT SENS INVERSE


Nous avons de la chance, ici, car les différentes classes possčde différents constructeur pouvant nous faciliter le travail par la suite.
Quels sont les différents constructeurs et comment se passe la construction au niveau des conteneurs ?
Construction d'un conteneur vide : L'appel d'un constructeur sans argument construit un conteneur vide, c'est-ŕ-dire ne comportant aucun élément.
Construction avec un nombre donné d'éléments : De façon comparable ŕ ce qui se passe avec la déclaration d'un tableau classique, l'appel d'un constructeur avec un seul argument entier « n » construit un conteneur comprenant « n » éléments. L'initialisation de ces éléments n'est correctement gérée que dans le cas ou les éléments sont des objets. En effet, ces derniers disposent d'un constructeur par défaut. Dans le cas des types primitifs, les valeurs sont aléatoires.
Construction avec un nombre d'éléments initialisés avec une valeur précise : Le premier argument fourni le nombre d'éléments alors que le second fixe la valeur d'initialisation.
Construction ŕ partir d'une séquence : Nous pouvons construire un conteneur ŕ partir d'une séquence d'éléments de męme type. Dans ce cas, nous fournissons simplement au constructeur deux arguments représentant les bornes de l'intervalle correspondant.
Construction par recopie : Chaque type de conteneur dispose de son propre constructeur de copie. Attention, il est nécessaire d'utiliser des conteneurs rigoureusement identiques (męme conteneur et męme type d'éléments).
! Vous pouvez remarquer que tout ce qui s’applique ŕ la classe « vector » peut s’appliqué ŕ des conteneurs séquentiels. !
Comment marche l'affectation ou bien la comparaison dans ces cas là ?
Il est possible d'affecter un conteneur d'un type donné ŕ un autre conteneur de męme type, c'est-ŕ-dire ayant le męme nom de patron et le męme type d'éléments.
Bien entendu, il n'est nullement nécessaire que le nombre d'éléments de chacun des conteneurs soit identique.
Les opérateurs relationnels « ==, !=, <, <=, >, >= », eux aussi, ont été redéfinis pour supporter tous les types de comparaison, quelque soit le conteneur utilisé. Jusqu’ ŕ présent, nous venons de voir certaines méthodes, trčs pratique et trčs simple d’ utilisation. Maintenant, je vais vous en montrer d’ autres, qui vont vous semblez commune ŕ certaines classes.
Jusqu’ ŕ présent, nous venons de voir certaines méthodes, trčs pratique et trčs simple d’ utilisation. Maintenant, je vais vous en montrer d’ autres, qui vont vous semblez commune ŕ certaines classes.
assign( début , fin ) : alors que l'affectation n'est possible qu'entre conteneurs de męme type, la méthode « assign » permet d'affecter, ŕ un conteneur existant, les éléments d'une autre séquence définie par un intervalle ( début , fin ), ŕ condition que les éléments des deux séquences soient de męme type.
assign( nombreDeFois , valeur ) : il existe également une version permettant d'affecter ŕ un conteneur, un nombre donné d'éléments ayant une valeur imposée.
clear() : vide le conteneur de son contenu.
empty() : teste si le conteneur est vide et renvoie true si c'est le cas, et false ans le cas contraire.
swap() : permet d'échanger le contenu de deux conteneurs de męme type.
insert( position , valeur ) : insčre une valeur avant l'élément pointé par la position.
insert( position , nombreDeFois , valeur ) : insčre un certain nombre de fois une valeur avant l'élément pointé par la position.
insert( début , fin , position ) : insčre les valeurs de l'intervalle ( début , fin ) avant l'élément pointé par la position.
push_back( valeur ) : cette méthode est spécialisée pour insérer une valeur en fin de conteneur ŕ la maničre d'une pile.
erase( position ) : supprime l'élément désigné par la position.
erase( début , fin ) : supprime les valeurs de l'intervalle « début ( compris ) , fin ( non compris ) ».
pop_back() : cette méthode est spécialisée pour supprimer la derničre valeur du conteneur ŕ la maničre d'une pile.
size() : détermine le nombre d'éléments que contient le conteneur.
Toutes ces ressemblances entre ces différentes classes, au niveau des méthodes, nous allons appeler cela :
« Les algorithmes génériques ».
Les conteneurs ont en commun beaucoup de méthodes. Chaque conteneur dispose également de méthodes supplémentaires qui font leur spécificité. Cependant, une fois que nous avons choisi un conteneur, il peut ętre intéressant de rajouter d'autres fonctionnalités non intégrées par le conteneur.
Dans ce cas lŕ, nous avons besoin des fonctions génériques. Rappelons que les fonctions génériques sont opérationnelles quelque soit le conteneur utilisé.
Nous remarquons, par exemple, que la recherche d'un élément au sein d'un conteneur ne fait pas parti des méthodes communes, alors que c'est un comportement qui est souvent souhaitable.
Nous allons d'ailleurs détailler un certain nombre de fonctions qui sont généralement assez utiles. Il faudra quand męme vérifier que votre conteneur ne dispose pas déjŕ de telles fonctions internes (méthodes).
Voici quelques fonctions génériques intéressantes
copy ( conteneur1début , conteneur1fin , conteneur2début ) : copie d'une séquence dans une autre. Il suffit de préciser l'intervalle désiré en donnant les itérateurs du premier conteneur. Cet intervalle est ensuite copié ŕ partir de l'itérateur donné par le second conteneur.
count ( iterateurdébut , iterateurfin , valeurRecherchée ) : comptabilise le nombre de fois qu'un élément est présent dans un conteneur,
iterateur find ( iterateurdébut , iterateurfin , valeurRecherchée ): recherche d'une valeur particuličre par rapport ŕ l'intervalle d'une séquence. La fonction retourne l'itérateur correspondant ŕ l'endroit oů se situe la valeur recherchée. Si la recherche n'a pas aboutie, la fonction renvoie un itérateur sur la fin de la séquence - conteneur.end().
iterateur max_element ( iterateurdébut , iterateurfin ): recherche la valeur maximale d'une séquence. La fonction retourne l'itérateur correspondant ŕ l'endroit oů se situe la valeur recherchée.
iterateur min_element ( iterateurdébut , iterateurfin ): recherche la valeur minimale d'une séquence. La fonction retourne l'itérateur correspondant ŕ l'endroit oů se situe la valeur recherchée.
replace ( iterateurdébut , iterateurfin , ancienneValeur, nouvelleValeur ) : remplace toutes les instances d'une valeur particuličre par une nouvelle valeur,
remove ( iterateurdébut , iterateurfin , valeurASupprimer ):supprime toutes les instances d'une valeur particuličre par rapport ŕ l'intervalle proposé.
sort ( iterateurdébut , iterateurfin ):tri de la séquence. Reclasse les éléments de l'intervalle proposé dans l'ordre croissant.
reverse ( iterateurdébut , iterateurfin ) : inverse l'ordre des éléments dans un conteneur.
! Il se pourrait que c' est le moment le plus important pour se plonger dans les différentes spécificités de la classe« vector ». !
Specificités du conteneur « vector »
Nous connaissons déjŕ la classe « vector » en tant que tableau et par ailleurs nous connaissons un certain nombre de méthodes qui sont communes ŕ tous les conteneurs. Nous allons découvrir, ici, d'autres méthodes qui sont propre ŕ la classe « vector ». Nous en profiterons pour déterminer les avantages et les inconvénients de ce type de conteneur.
Ce conteneur représente bien un tableau, c'est-ŕ-dire que les éléments qui constituent la séquence, sont placés dans des cases mémoires contiguës.
Ce conteneur « vector » est relativement performant, puisqu'il s'agit en fait d'un tableau dynamique, c'est-ŕ-dire, que suivant le besoin, le nombre de cases qui composent le tableau peut augmenter en cours d'utilisation.
Si le tableau est plein, lorsque nous essayons d'introduire une nouvelle valeur, la gestion interne du vecteur prévoit de réserver un nouvel emplacement mémoire dont la capacité est le double de la précédente, ensuite une copie des anciennes valeurs est effectuée vers ce nouvel emplacement. La copie d'anciennes valeurs prend du temps, c'est pour cette raison que la nouvelle capacité est doublée.
Dans cette situation, nous avons un bon compromis entre la capacité du tableau (utiliser le moins de place possible) et le temps de réponse en général (répondre le plus rapidement possible ŕ une requęte).
Du coup, il faut noter que la capacité du tableau peut ętre plus grande que le nombre d'éléments déjŕ introduits dans le conteneur. Cette classe propose un certain nombre de méthodes qui permet de contrôler cette situation. Ci-dessous, se trouve l'ensemble des méthodes spécifiques ŕ la classe « vector » :
back() : récupčre la valeur du dernier élément sans toutefois l'enlever du conteneur comme c'est le cas avec la méthode pop_back() .
front() : récupčre la valeur du premier élément sans l'enlever du conteneur.
size() : cette méthode n'est pas spécifique ŕ « vector », toutefois, je rappelle que cette méthode retourne le nombre d'éléments présents dans le conteneur.
capacity() : retourne la capacité du tableau (nombre de cases allouées) au moment de la consultation. « capacity() >= size() » .
reserve( taille ) : permet d'imposer une capacité.
Quel est l 'intérêt d 'utiliser la classe « vector » ?
ATTENTION : NE PAS OUBLIER D’ECRIRE "#include vector
! Cette inclusion est obligatoire si l’ on souhaite utilisé des vecteurs !
Le conteneur vector présente deux caractéristiques essentielles :
Comme les cases mémoires relatives aux éléments sont contiguës, nous savons que l'élément qui suit un autre se trouve sur la case d'aprčs, ainsi, il n'est pas nécessaire de rajouter de pointeurs supplémentaires pour parcourir un conteneur, comme c'est le cas avec une liste. Ainsi, la taille mémoire que prend ce type de conteneur est relativement réduite.
Il s'agit en fait d'un tableau, et grâce ŕ l'opérateur d'indexation « [ ] », nous pouvons accéder directement ŕ un élément du conteneur sans ętre obligé de parcourir toute la séquence. L'accčs aléatoire est donc trčs rapide. Nous pouvons męme nous passer de l'écriture explicite d'un « iterator ». Généralement, nous utilisons plutôt la syntaxe des itérateurs pour conserver une certaine homogénéité, plus tard, il sera alors plus facile de changer de type de conteneur si le besoin s'en fait sentir. (Comme le vecteur est un tableau, l'itérateur correspond, dans ce cas, lŕ ŕ l'adresse d'une des cases du tableau).
Ce type de conteneur est également trčs bien adapté ŕ l'insertion de nouveaux éléments en fin de conteneur, ce que fait trčs bien la méthode push_back() .
Conteneur deque : Le conteneur qui lui ressemble beaucoup, c'est le conteneur « deque » qui offre la possibilité d'insérer « push_front() » et de supprimer « pop_front() » de nouveau éléments en début de conteneur, ce que ne permet pas le conteneur « vector ». « deque », par contre, ne possčde pas la gestion de la capacité du tableau.
Quel est l 'intérêt d ' utiliser la classe « list » ?
ATTENTION : NE PAS OUBLIER D’ECRIRE #include <list>
Cette inclusion est obligatoire si l’ on souhaite utilisé des méthodes de cette classe dans de bonnes conditions.
Si vous avez justement besoin de gérer beaucoup d'insertions et de suppressions, la liste est totalement adaptée ŕ ce genre de situation. Elle dispose également de méthodes fort intéressantes qui évitent d'utiliser les fonctions génériques. Elle dispose, par exemple, de sa propre méthode de tri, ce que ne permet pas le conteneur « vector ».
Ce conteneur est implémenté par une liste en double chaînage, ce qui fait que chaque élément est constitué de deux pointeurs supplémentaires.
Du coup, la taille mémoire est plus conséquente que pour le conteneur « vector ».
Pour atteindre un élément, vous ętes obligé de parcourir jusqu'ŕ l'élément désiré afin de pouvoir l'atteindre. Le temps de réponse pour accéder ŕ un élément peut donc ętre trčs important. Dans ces conditions, ŕ vous de choisir le conteneur qui offre le plus de souplesse possible pour votre application, et ceci sans trop de contraintes.
Ci -dessous , se trouve l' ensemble des méthodes spécifiques à la classe « list »
remove( valeur ) : supprime tous les éléments égaux ŕ valeur. Cette méthode remplace essaiment la fonction générique équivalente, ainsi que la méthode erase() commune ŕ tous les conteneurs.
sort() : tri la liste. Reclasse les éléments dans l'ordre croissant. Dans le cas d'un tri d'une liste, c'est cette méthode qu'il faut utiliser. Il ne faut pas prendre la fonction générique algorithmique équivalente.
unique() : permet d'éliminer les éléments en double, ŕ condition de la faire porter sur une liste préalablement triée.
merge( liste ) : fusionne liste avec la liste concernée. Attention, ŕ la fin de cette opération, liste est vide.
splice( position , liste_origine ) :
splice( position , liste_origine , position_origine ) :
splice( position , liste_origine , début_origine ,fin_origine ) : permet de déplacer des éléments d'une autre liste dans la liste concernée. Attention, comme avec merge(), les éléments déplacés sont supprimés de la liste d'origine et pas seulement copiés.
Maintenant, nous allons approfondir la suppression d’ un élément dans un conteneur « list ».
Comment est réalisé cette suppression et de quoi elle en découle ?
Voici la réponse avec une petite illustration :
Lorsque vous désirez supprimer une valeur de la liste, il suffit alors de redéfinir un des pointeurs de l'élément suivant ainsi qu'un des pointeurs de l'élément précédent.


Comment est composé la bibliothèque standard ?
Nous avons encore des multiples choses ŕ voir comme les adaptateurs de conteneur.
Qu ' est ce qu ' un adaptateur de conteneur ?
La bibliothčque standard dispose de deux patrons particuliers stack et queue dits adaptateurs de conteneurs.
Il s'agit de classes génériques construites sur un conteneur séquentiel qui en modifie l'interface, ŕ la fois en la restreignant et en l'adaptant ŕ leurs propres fonctionnalités.
Ils disposent tous d'un seul constructeur qui est le constructeur par défaut.
! D’ aprčs notre professeur de programmation, « stack » et « deque » ne sont pas ŕ savoir par coeur en BTS IRIS. Il faut simplement y jeter un oeuil. !
! Cela étant dit, pour ceux qui veulent aller plus loin, il n’ y a pas de soucis ŕ avoir car je vais continuer ŕ expliquer. !
L ' adaptateur « stack »
La classe générique stack est destinée ŕ la gestion des piles de type LIFO (Last In, First Out) ; il peut ętre construit ŕ partir de l'un des trois conteneurs séquentiels vector, deque, list.
Ci-dessous, nous pouvons voir comment créer cet adaptateur :

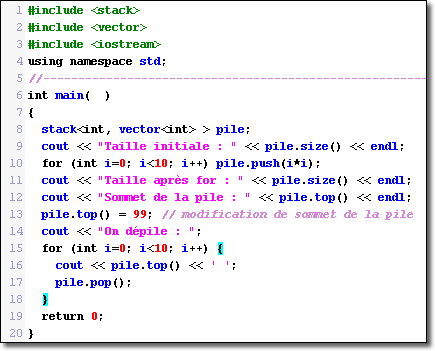
Dans un tel conteneur, on ne peut qu'introduire push() des informations qui s'empile les unes sur les autres et que l'on recueille, ŕ raison d'une seule ŕ la fois, en extrayant la derničre introduite.
Nous trouvons uniquement les méthodes suivantes :
empty() : renvoie true si la pile est vide.
size() : fournit le nombre d'éléments de la pile.
top() : accčs ŕ l'information située au sommet de la pile que nous pouvons consulter ou męme modifier (sans la supprimer).
push( valeur ) : place valeur sur le sommet de la pile.
pop() : suppression de l'élément situé au sommet de la pile (ne retourne aucune valeur).
Illustration :

L ' adaptateur « deque »
La classe générique queue est destinée ŕ la gestion de piles de files d'attentes de type FIFO (First In, First Out).
Dans ce cas lŕ, les informations sont placées ŕ la fin du conteneur et peuvent ętre ensuite récupérées au début.
Un tel conteneur peut ętre construit ŕ partir de l'un des deux conteneurs séquentiels deque, list.
Le conteneur vector n'est pas approprié puisqu'il ne dispose pas d'insertions efficaces au début.
empty() : renvoie true si la pile est vide.
size() : fournit le nombre d'éléments de la pile.
front() : accčs ŕ l'information située en tęte de la file que nous pouvons consulter ou męme modifier (sans la supprimer).
back() : accčs ŕ l'information située ŕ la fin de la file que nous pouvons consulter ou męme modifier (sans la supprimer).
push( valeur ) : place valeur dans la file.
pop() : suppression de l'élément situé en tęte de la file (ne retourne aucune valeur).
Illustration :


Nous obtenons ce résultat aprčs avoir écrit ce bout de code.
Les conteneurs se classent en deux catégories :
->les conteneurs séquentiels
->les conteneurs associatifs
Nous venons de le voir, les conteneurs séquentiels sont ordonnés suivant un ordre imposé explicitement par le programme lui-męme ; nous accédons ŕ un des éléments en tenant compte cet ordre, que nous utilisions un indice ou un itérateur.
Les conteneurs associatifs ont pour principale vocation de retrouver une information, non plus en fonction de sa place dans le conteneur, mais en fonction de sa valeur nommée « clé ».
Par exemple, un répertoire téléphonique, dans lequel on retrouve le numéro de téléphone ŕ partir de la clé formée du nom de la personne concernée. Malgré tout, pour de simple questions d'efficacité, un conteneur associatif se trouve ordonné intrinsčquement en permanence, en se fondant sur une relation (par défaut « < ») choisie ŕ la construction.
Les deux conteneurs associatifs les plus importants sont map et multimap. Ils correspondent pleinement au concept de conteneur associatif, en associant une clé et une valeur.
Mais, alors que map impose l'unicité des clés, autrement dit l'absence de deux éléments ayant la męme clé, multimap ne l'impose pas et nous pourrons trouver plusieurs éléments d'une męme clé qui apparaîtront alors consécutivement.
Si nous reprenons l'exemple du répertoire téléphonique, multimap autorise la présence de plusieurs numéros pour une męme personne, tandis que map ne l'autorise pas.
Comment est régie le conteneur « map » , comment l'utiliser à bonne escient ?
Ce conteneur offre une grande souplesse d'emploi.
Il permet effectivement d'intégrer ou de rechercher des éléments ŕ l'aide de l'opérateur d'indexation [ ] sans se préoccuper spécialement de l'endroit oů le conteneur stocke sa donnée.
Bien entendu, un certain nombre de méthodes sont proposés pour faciliter l'utilisation de ce type de conteneur.
empty() : renvoie true si le conteneur « map » est vide.
size() : fournit le nombre d'éléments du conteneur.
clear() : vide le conteneur de tout élément.
Objetmap[ clé ] = valeur : place le couple ( clé , valeur ) dans le conteneur Objetmap .
valeur = Objetmap[ clé ] : recherche la valeur associée ŕ clé dans le conteneur Objetmap et la retourne ŕ valeur .
erase( clé ) : supprime un élément du conteneur référencé par clé .
begin(), end(), rbebin(), rend() : il est possible de parcourir le conteneur afin, par exemple, de recenser l'ensemble des éléments. Chacune de ces méthodes retourne un itérateur.
iterator , reverse_iterator : Pour permettre ce parcours, comme tous les autres conteneurs, nous nous servons donc itérateurs.
first, second : il existe deux attributs qui représentent respectivement la clé et la valeur d'un élément du conteneur.
insert( élément ) : bien que nous ayons pour ce conteneur l'opérateur d'indexation qui permet d'introduire de nouveaux éléments de façon intuitive, nous pouvons également utiliser cette méthode. En paramčtre, il est nécessaire de passer l'élément en entier, c'est-ŕ-dire le couple ( clé , valeur ). Pour cela, « élément » sera fabriqué ŕ l'aide de la fonction « make_pair » définie ci-dessous.
make_pair( clé , valeur ) : cette fonction générique permet de fabriquer un élément du conteneur « map » constitué d'une clé et d'une valeur .
Itérateur find( clé ) : bien que nous ayons pour ce conteneur l'opérateur d'indexation qui permet de rechercher une valeur , il est également possible d'utiliser cette méthode qui retourne un itérateur qui identifie l'emplacement de l'élément référencé par la clé passée en paramčtre. Si aucun élément n'est retrouvé, la méthode renvoie l'itérateur relatif ŕ « end() ».
Illustration de ce que l’on vient de voir :


Comment est régie le conteneur « multimap » , comment l 'utiliser à bonne esc ient ?
Le conteneur multimap est un conteneur map qui accepte en plus d'avoir plusieurs valeurs pour une męme clé.
Nous retrouverons donc les męmes méthodes, sauf pour l'opérateur d'indexation puisque, dans ce cas lŕ, l'utilisation d'un tel opérateur ne conviendrait pas.
Il faut donc impérativement utiliser la méthode « insert( élément ) » associée ŕ la fonction générique « make_pair( clé , valeur ) » pour palier ce manque.
La méthode « erase( clé ) » cette fois ci permet d'effacer toutes les valeurs associées ŕ une męme clé.
Par contre, il faut pouvoir parcourir l'ensemble des valeurs associées ŕ une męme clé. D'autres méthodes qui existées déjŕ dans le conteneur map prennent maintenant toute leur utilité.
count( clé ) : retourne le nombre d'éléments associés ŕ une clé.
Itérateur lower_bound( clé ) : retourne un itérateur sur le premier élément associé ŕ clé.
Itérateur upper_bound( clé ) : retourne un itérateur juste aprčs le dernier élément associé ŕ clé.
Illustration de ce que l’ on vient de voir :


, cin et cout. Du moins nous semblons les connaître. Cette étude nous permettra de découvrir un certain nombre de méthodes associées qui peuvent rendre de grands services.
Par ailleurs, nous allons étendre plus généralement nos connaissances sur les classes qui représentent l'ensemble des flots.
Ainsi, nous pourrons travailler aussi bien sur les entrées/sorties standards que sur des fichiers ou que sur les flots en mémoire pour la gestion et le formatage des chaînes de caractčres.
Nous pourrons męme modifier le comportement standard de ces flots afin de permettre ŕ nos propres classes de pouvoir s'intégrer aux classes représentatives de ces flots.
! Une question s’ impose maintenant, comment est organisée ces classes trčs utiles. Existe – t’il une hiérarchie de ces classes représentant les flots et les fichier. Et bien oui, nous y allons arriver. !
Hiérarchie des classes représentant les flots
Il existe un certain nombre de classes qui s'occupent de la gestion des flots. De plus, chaque classe est spécialisée afin de répondre parfaitement ŕ l'adéquation recherchée. Ainsi, vous avez des classes réservées pour la gestion des fichiers, d'autres pour le traitement des flots en mémoire sous forme de chaînes de caractčres, etc. par ailleurs, ces classes ne sont pas disposées n'importe comment, mais elles font toutes parties d'une męme famille et profitent pleinement du polymorphisme dont les conséquences seront pleinement justifiées lorsque nous aborderons la fin de notre étude. Vous en avez une vue dans le diagramme UML ci dessous.
Sur le diagramme UML ci-dessous, nous pouvons voir qu’il y a une hiérarchie trčs compliqué qui existe en C++:

! Jusqu’ ŕ présent nous utilisions que trčs peu de classes ici présente. !
Les classes qui nous servirons presque tout le temps seront les suivantes :
-> classe ostream, pour les sorties.
-> classe istream, pour les entrées.
-> classe iostream, pour les deux sens.
Que signifie l 'expression « flots d 'entrée / sortie ?
D'une maničre générale, un flot peut ętre considéré comme un « canal » qui permet une communication avec un périphérique ou un fichier ou męme une partie de la mémoire (formatée comme une structure de fichier).
Il existe trois types de flots :
Recevant de l'information - flot de sortie.
Fournissant de l'information - flot d'entrée.
Recevant et fournissant de l'information - flot d'entrée et de sortie.
Toutes les opérations d'entrées et de sorties sont fournies par les classes istream (flot d'entrée), ostream (flot de sortie) et iostream (classe dérivée des deux premičres qui permet donc la bidirectionnalité).
Ainsi, l'étude que nous ferons sur ces trois classes particuličres sera également utile pour toutes les autres qui dérivent de celles-ci.

Il existe quatre objets prédéfinis qui permet de gérer les flux standard, savoir :
cin : objet de la classe istream représentant l'entrée standard. En général, cin permet de lire les données depuis le terminal de l'ordinateur, c'est-ŕ-dire le clavier.
cout : objet de la classe ostream représentant la sortie standard. En général, cout permet d'écrire des données pour le terminal de l'ordinateur, c'est-ŕ-dire l'écran.
cerr : objet également de la classe ostream représentant les erreurs standard. cerr est l'emplacement vers lequel diriger les messages d'erreur du programme.
clog : objet supplémentaire qui gčre les erreurs qui est donc similaire ŕ cerr. Il dispose en plus d'un tampon intermédiaire.
! Dans nos programme, nous utilisons beaucoup les deux premičres fonctions « cin » et « cout », n’est ce pas ?. !
Les classes istream et ostream sont prépondérantes puisque c'est ŕ partir de ces classes que nous pouvons réellement communiquer. Elles disposent d'ailleurs d'un certain nombre de méthodes que nous allons détailler. Elles ont tellement d'importances qu'il a été décidé d'utiliser les opérateurs de redirection pour permettre une utilisation rapide et pratique. Le sens de redirection n'est pas choisi au hasard.
En effet, le sens proposé indique la direction de l'envoi des données. Ainsi, dans le cas général :
>> x ; // insčre des données dans x.
<< x ; // extrait des données de x.
En prenant l'exemple des flots que nous connaissons :
cin >> x ; // insčre les données saisies au clavier dans x.
cout << x ; // extrait des données de x et l'affiche ŕ l'écran.
Dans le modčle UML, les deux opérateurs ne sont écrits qu'une seule fois, alors qu'ils sont surdéfinis pour permettre la communication avec différents types de variables.
Ainsi, nous serons capable de saisir et d'afficher aussi bien des entiers que des réels, des chaînes de caractčres, etc. En fait, tous les types primitifs ainsi que ceux faisant parti de la STL pourront ętre utilisés directement par les flots.
Seuls les types définis par l'utilisateur ne sont pas intégrés. Il sera alors nécessaire de proposer de nouvelles surdéfinitions pour élargir les compétences de ces flots, ce que nous ferons ŕ l'issu de ce cour.
Détaillions maintenant les différentes classes qui vont nous intéresser.
! Je sens que vous ętes poussé par la curiosité d’ en savoir plus, moi je suis heureux de vous montrer tout cela, encore merci de pręter attention ŕ tout ce que je fais. J’ arręte tout cela pour passer ŕ la suite de mon cours. !
La classe « ostream »

En écoutant mon professeur de programmation, j'ai compris que la classe « ostream » contenait quelques méthodes supplémentaire.
Voici ces méthodes, qui sont trčs importante.
ostream& operator<< (type) ;
Transfčre une information d'un type prédéfini sur le flot de sortie. Comme l'opérateur renvoie un ostream, il est possible de proposer un enchaînement d'opérations.
Voici un exemple:
int x = 5 ;double y =-6.3 ;cout << x << y ; // envoie la valeur 5 et la valeur -6.3 ŕ l'écran.
ostream& put (char ) ;
Cette méthode transmet un seul caractčre dans le flot donné par l'argument. Cette méthode est souvent associée ŕ la méthode get de istream.
Comme cette méthode renvoie un ostream, il est possible de proposer un enchaînement d'appels successifs au męme titre que l'opérateur « << ».
cout.put(µA') ; // envoie le caractčre µA' ŕ l'écran, équivalent ŕ : cout << µA' ; cout.put(µA').put(µB').put(µC') ; // envoie les trois
ostream& write (const char*, int) ;
Cette méthode fournit une alternative ŕ l'opérateur « << » pour transmettre un tableau de caractčres. Elle transmet en sortie une certaine longueur de caractčres (quels que soient ces caractčres). La méthode write ne fait donc pas intervenir de caractčres de fin de chaîne ; si un tel caractčre apparaît dans la longueur prévue, il sera transmis, comme les autres, au flot de sortie. Son comportement est donc totalement différent de l'opérateur « << » puisque ce dernier affiche justement tous les caractčres jusqu'ŕ ce qu'il rencontre le caractčre de fin de chaîne.
char message[] = « Bonjour » ; cout.write(message, 4) ; // affiche les quatre premierscaractčres de message ŕ l'écran.
Cette méthode n'est pas trčs utile pour un écran, mais elle le deviendra lorsque nous traiterons des informations brutes sans aucun formatage particulier (informations binaires) directement dans un fichier.
ostream& flush ( ) ;
Cette méthode vide explicitement la mémoire tampon.
La classe « istream »

La classe « istream » hérite de la classe « IOS », grâce ŕ cette héritage, nous pouvons tester le flot de donnée grâce ŕ l’ opérator () .
(flot) // ou flot représente n'importe qu'elle classe de la hiérarchie des flots.
Le résultat est :
true : si aucun des bits d'erreur n'est activé.
false : dans le cas contraire.
Lorsque nous écrivons :
!flot ou ( !flot) // ou flot représente n'importe qu'elle classe de la hiérarchie des flots.
Le résultat est :
false : si aucun des bits d'erreur n'est activé.
true : dans le cas contraire.
Nous allons utiliser cette caractéristique dans la classe « istream » puisqu'elle hérite de tout le comportement de la classe « ios ».
! De plus, nous allons voir tout ce qui faut retenir de cette classe (les opérateurs, les méthodes qui sont les plus souvent utilisé ŕ notre niveau).!
istream& operator>> (type) ;
Son rôle consiste ŕ extraire du flot concerné les caractčres nécessaires pour former une valeur du type voulu en réalisant une opération inverse du formatage opéré par l'opérateur « << ».
int x ; double y ; cin >> x >> y ; // saisie ŕ partir du clavier et transfert des valeurs vers les variables x et y.
Ici dans cet exemple, il est nécessaire de se servir de séparateurs pour faire la différence entre la valeur prévue pour x et celle prévu pour y .
Comment peut-on séparer x et y ?
Pour cela, nous avons le choix parmi les délimiteurs qui suivent :
espace «' ' », tabulation horizontale « \t », tabulation verticale « \v », fin de ligne « \n », changement de page « \f ».
Par conséquence, les délimiteurs ne peuvent pas ętre lus en tant que caractčres.
Ainsi, aprčs la déclaration suivante :
char message[50] ;
Or, lorsque que l’ on saisie au clavier la chaîne suivante : « bonjour ŕ tout le monde », seule la valeur « bonjour » est récupérée dans la variable message puisque l'espace est considéré comme un délimiteur.
Il faudra donc utiliser une autre méthode pour récupérer la totalité de la chaîne saisie, notamment la méthode getline() .
Soit l'écriture suivante :
vector
L'expression : while (cin >> ival) lit une séquence de valeurs depuis l'entrée standard jusqu'ŕ ce que cin soit évalué ŕ false.
Deux conditions générales sont ŕ l'origine de l'évaluation de istream ŕ false :
1. La lecture d'une fin de fichier (auquel cas, toutes les valeurs contenues dans le fichier ont été correctement lues), ou la détection d'une valeur invalide tel 3.14159 (cette valeur est un réel, et c'est un entier qui est attendu).
2. Dans le cas de la lecture d'une valeur invalide, l'objet cin est placé en état d'erreur et la lecture des valeurs s'interrompt.
istream& getline (char * chaîne , int taille , char délimiteur = µ \n' ) ;
Cette méthode facilite la lecture des chaînes de caractčres (non « string »), ou plus généralement d'une suite de caractčres quelconques (espace ou caractčres de contrôle compris), terminé par un caractčre qui sert de délimiteur et qui n'est donc pas utiliser par la chaîne ŕ récupérer.
Cette méthode doit donc ętre utiliser ŕ la place de l'opérateur de redirection « >> » pour saisir des chaînes comportant plusieurs mots (séparés par des espaces) ou męme tout un texte écrit sur plusieurs lignes, auquel cas, il ne faut pas prendre le caractčre proposé par défaut « \n ».
Cette méthode lit des caractčres sur le flot l'ayant appelé et les places dans l'emplacement désigné par chaîne. Elle s'interrompt lorsqu'une des deux conditions suivantes est respectée :
le caractčre qui sert de délimiteur a été trouvé : dans ce cas ce caractčre n'est pas recopié en mémoire ;
taille-1 caractčres ont été lus.
Dans tous les cas, cette méthode ajoute le caractčre nul de terminaison de chaîne ŕ la suite des caractčres lus.
cin.getline(chaine, 50);
Juste au dessus, nous pouvons voir comment utiliser cette méthodes ŕ bonne escient.
Avec :
-> chaine :représentant la variable oů va ętre stockée ce que l’ opérateur va taper sur le clavier.
-> 50 : Nombre de caractčres stockés dans cette chaine.
istream& read (char * chaîne , int taille )
Cette méthode permet de lire sur le flot d'entrée considéré une suite de caractčres (octets) en spécifiant la longueur voulue.
char chaine[20]; cin.read(chaine, 5) ; // récupčre uniquement 5 caractčres du tampon du clavier męme si il en possčde plus.
Ici encore cette méthode peut sembler faire double emploi, soit avec la lecture d'une chaîne avec l'opérateur « >> », soit avec la méthode getline.
Toutefois, read ne nécessite ni séparateur de fin de chaîne, ni délimiteur particulier.
Cette méthode est plus couramment utilisée, comme la méthode write, lorsque nous souhaiterons accéder ŕ des fichiers sous forme binaire, c'est-ŕ-dire en recopiant en mémoire les informations telles qu'elles figurent dans le fichier.
Quelle est le formatage de l’ information employé sur un flot de donnée?
Chaque objet flot conserve en permanence un ensemble d'indicateurs spécifiant quel est, ŕ un moment donné, son statut de formatage.
Ces indicateurs servent ŕ contrôler, par exemple, l'affichage des valeurs entičres suivant la base désirée (décimal, octal, hexadécimal), ou bien encore, permet de contrôler la précision des nombres ŕ virgule flottante.
Bien d'autres possibilités de formatage sont offertes.
Ces indicateurs sont positionnés avec des valeurs par défaut, ce qui permet ŕ l'utilisateur d'ignorer totalement cet aspect, tant qu'il se contente de l'affichage par défaut. Un des avantages de ce systčme est de permettre ŕ celui qui le souhaite, de définir, une fois pour toutes, un format approprié ŕ une application donnée et de plus avoir ŕ s'en soucier par la suite.
Le programmeur dispose de manipulateurs prédéfinis pour modifier l'état de format d'un objet flot. Un manipulateur s'applique ŕ l'objet flux comme s'il s'agissait d'une donnée. Toutefois, au lieu de déclencher la lecture ou l'écriture des données, le manipulateur modifie en fait l'état interne de l'objet flux.
Pour vous montrez comment nous utilisons les flots, nous allons voir deux syntaxes :
1. Flot << manipulateur pour un flot de sortie.
2. Flot >> manipulateur pour un flot d'entrée.
Voyons maintenant, quelques classes trčs utiles dans nos programmes.
Inclusion de la classe « iostream .h »
#include <iostream> // Cette inclusion est obligatoire pour utiliser les manipulateurs ci-dessous |
|
dec / hex / oct |
Base de numération pour les valeurs entières, respectivement : décimal, hexadécimal, octal. |
ends |
Insère le caractère de fin de chaîne nul, puis vide le tampon. |
endl |
Insère une nouvelle ligne, puis vide le tampon. |
left |
Ajoute des caractères de remplissage à droite de la valeur. |
right |
Ajoute des caractères de remplissage à gauche de la valeur. |
boolalpha / noboolalpha |
Représente true et false sous forme de chaînes / Représente true et false au format 0 , 1 |
showbase / noshowbase |
Génère (ou pas) un préfixe indiquant une base numérique |
showpoint / noshowpoint |
Affichage du point décimal lorsqu'on utilise des réels et qu'il n'y a pas de parties décimales. |
uppercase / nouppercase |
Affichage des caractères hexadécimaux en majuscule. |
showpos / noshowpos |
Affichage des nombres positifs précédés du signe + |
skipws / noskipws |
Saute (ou pas) l'espace avec les opérateurs d'entrée. |
scientific / fixed |
Notation scientifique des nombres réels : 1.5 e+01 , ou « point fixe » pour les nombres réels : 10.5 |
ws |
« Mange » l'espace |
Avec ce type de manipulateur, nous n'avons pas besoin de repréciser le męme traitement pour les variables qui suivent. Une fois que l'on place un manipulateur, il reste actif. Si vous désirez réobtenir le comportement par défaut, vous devez appliquez le manipulateur adéquat.
Il existe également des manipulateurs paramétriques qui représente des valeurs numériques et non plus une information tout ou rien. Le principe est similaire aux manipulateurs précédents, toutefois, ils comportent en plus un paramčtre qui récupčre la valeur spécifiée. Ces manipulateurs vous sont présentés dans la page suivante.
Inclusion de la classe « iomanip. h »
#include <iomanip.h> // Cette inclusion est obligatoire pour utiliser les manipulateurs paramétrés ci-dessous |
|
setw (nombre) |
Définit le gabarit de la variable à afficher avec une justification à droite par défaut. Si la valeur à afficher est plus importante que le gabarit, cette valeur ne sera pas tronquée et sera donc affichée de façon conventionnelle. Le manipulateur setw doit être utilisé pour chacune des informations à afficher. |
setfill (caractère) |
Définit le caractère de remplissage lorsqu'on utilise un affichage avec la gestion de gabarit. Par défaut, le caractère de remplissage est l'espace. |
setprecision (nombre) |
Permet de définir le nombre de chiffres significatifs pour les nombres réels. C'est uniquement pour l'affichage, la variable garde sa précision, et la valeur affichée est arrondie. Lorsque l'on utilise au préalable le manipulateur fixed , le manipulateur setprecision permet d'indiquer le nombre de chiffres significatifs après la virgule. |
setbase(base) |
Spécifie la base d'affichage sur les nombres entiers. |
En ce qui concerne setw, sachez que ce manipulateur définit uniquement le gabarit de la prochaine information ŕ écrire. Si l'on ne fait pas de nouveau appel ŕ setw pour les informations suivantes, celles-ci seront écrites suivant les conventions habituelles, ŕ savoir en utilisant l'emplacement minimal nécessaire pour les écrire.
Je vais vous montrer la hiérarchie des classes concernant les fichiers. Au niveau de l’ écriture et de la lecture, le tout pour que vous arrivez ŕ comprendre ce qu’ il y a derričre.

Les classes que l’ on utilisera le plus souvent sont celle entourer de rouge, ŕ savoir :
1. ofstream : flot de sortie associé ŕ un fichier. Permet
d'écrire des informations de type quelconque dans un
fichier.
2. ifstream : flot d'entrée associé ŕ un fichier. Permet de
lire des informations de type quelconque issues du
fichier.
3. fstream : flot bidirectionnel associé ŕ un fichier. Permet d'écrire ou de lire dans un
fichier.
! Une seule question doit vous venir ŕ l’esprit de curiosité. ! Existe-t-il des modes d’ ouvertures de fichiers ?
En voici un tableau, regroupant ces différents modes.
Bits d'ouverture de fichier dans le mot d'état open_mode |
|
in |
Ouverture en lecture. Le fichier doit exister. |
out |
Ouverture en écriture. Ecrase l'ancien contenu. Si le fichier n'existe pas, il est automatiquement créé. |
app |
Ouverture en ajout de données (écriture en fin de fichier). |
trunc |
Si le fichier existe, son contenu est définitivement perdu. |
binary |
Pour les précédents modes, l'information été systématiquement transformée en une suite de caractère. Dans l'exemple précédent, nous avons sauvegardé un certain nombre de valeurs de type différent. Au moment du transfert vers le fichier, ces valeurs subissent une transformation pour devenir une suite de caractères. Il est alors possible de contrôler le contenu du fichier avec un simple éditeur de texte. Toutefois, vous pouvez désirer conserver le type original et donc demander à avoir un stockage sous forme binaire. C'est ce que permet ce mode d'ouverture. |
Signatures des méthodes et choix du mode d ' ouverture d'un fichier
ifstream
• ifstream (); : constructeur par défaut
• ifstream (const char *nomfichier, ios_base::open_mode
mode = ios_base::in) ; : Constructeur. Les arguments
transmis au constructeur spécifient, tour ŕ tour, le nom
du fichier ŕ ouvrir et le mode d'ouverture. Par défaut,
pour cette classe, le fichier est ouvert en lecture.
• bool is_open () const ; : détermine si le fichier
représenté par l'objet est ouvert.
• void open (const char *nomfichier, ios_base::open_mode mode = ios_base::in) ; : Ouvre le fichier représenté par
l'objet en mode lecture (par défaut).
• void close () ; : ferme le fichier représenté par l'objet.
ofstream
• ofstream (); : constructeur par défaut
• ofstream (const char *nomfichier, ios_base::open_modemode = ios_base::out) ; : Constructeur. Les arguments
transmis au constructeur spécifient, tour ŕ tour, le nom
du fichier ŕ ouvrir et le mode d'ouverture. Par défaut,
pour cette classe, le fichier est ouvert en écriture.
• bool is_open () const ; : détermine si le fichier
représenté par l'objet est ouvert.
• void open (const char *nomfichier, ios_base::open_modemode = ios_base::out) ; : Ouvre le fichier représenté
par l'objet en mode écriture (par défaut).
• void close () ; : ferme le fichier représenté par l'objet.
fstream
• fstream (); : constructeur par défaut
• fstream (const char *nomfichier, ios_base::open_modemode = ios_base::in | ios_base::out) ; : Constructeur.
Les arguments transmis au constructeur spécifient, tour ŕ
tour, le nom du fichier ŕ ouvrir et le mode d'ouverture.
Par défaut, pour cette classe, le fichier est ouvert ŕ la fois
en lecture et en écriture.
• bool is_open () const ; : détermine si le fichier
représenté par l'objet est ouvert.
• void open (const char *nomfichier, ios_base::open_mode
mode = ios_base::in | ios_base::out) ; : Ouvre le fichier
représenté par l'objet en mode lecture et écriture (par
défaut).
• void close () ; : ferme le fichier représenté par l'objet.
Dans ces classes, les modes d'ouvertures sont positionnés avec des paramčtres par défaut, ce qui convient dans la plupart des cas.
Il est toutefois possible de proposer un autre comportement. Nous avons, par exemple, souvent besoin d'ouvrir un fichier en mode ajout.
Il faut donc prendre la classe ofstream qui permet d'écrire dans un fichier et changer le mode par défaut. Ainsi :
ofstream fichier('nom du fichier´, ios::app);
Et si nous voulons fabriquer un fichier pour écrire des valeurs enregistrées sous forme brute :
ofstream fichier('nom du fichier´, ios::out | ios ::binary)
Accès direct à une position absolue dans le fichier
Le terme flot indique bien que nous soutirons l'information ŕ la volée sous forme séquentielle.
L'accčs direct est implémenté sous la forme d'un pointeur de fichier, c'est-ŕ-dire un nombre précisant le rang du prochain « octet » ŕ lire ou ŕ écrire.
Aprčs chaque opération de lecture ou d'écriture, ce pointeur est incrémenté du nombre d'octets transférés. Ainsi, lorsque nous n'agissons pas explicitement sur ce pointeur, nous réalisons en fait un accčs séquentiel classique; c'est d'ailleurs ce que nous avons fait jusqu'ŕ présent.
Attention, l'accčs direct n'est possible qu'en considérant le fichier que sous forme d'une suite d'informations binaires.
Finalement, les possibilités d'accčs direct se résument donc aux possibilités d'action sur ce pointeur ou ŕ la détermination de sa valeur.
Des méthodes héritées respectivement de istream et de ostream permettent de se déplacer ŕ une adresse absolue ŕ l'intérieur du fichier ou ŕ une distance en octets depuis une position donnée.
1. La méthode seek permet de positionner le pointeur de
fichier ŕ un endroit précis.
2. La méthode tell permet de donner la position actuelle du
pointeur de fichier.
En fait, le nom de ces méthodes possčde une lettre supplémentaire suivant qu'elles dérivent de istream ou de ostream.
Dans le premier cas, les méthodes issues de istream possčdent le suffixe g (pour get).
Dans le deuxičme cas, les méthodes issues de ostream possčdent le suffixe p (pour put).
Par ailleurs, des constantes ont été spécialement conçues pour indiquer respectivement, le début du fichier, la fin du fichier, ou la position courante du fichier.
Ce qui donne dans les différentes classes :
istream
• istream& seekg (int pos_courante) ; Le pointeur de fichier pointe sur
la position absolue pos_courante.
• istream& seekg (int pos_relative, ios_base::seekdir
origine) ; Le pointeur de fichier pointe relativement ŕ la position pos_relative
par rapport ŕ l'origine fixée par le deuxičme argument.
• int tellg () ; renvoie la position courante du pointeur de fichier.
ostream
• ostream& seekp (int pos_courante) ; Le pointeur de fichier pointe
sur la position absolue pos_courante.
• ostream& seekp (int pos_relative, ios_base ::seekdir
origine) ; Le pointeur de fichier pointe relativement ŕ la position
pos_relative par rapport ŕ l'origine fixée par le deuxičme argument.
• int tellp () ; renvoie la position courante du pointeur de fichier.
ios_ base
• ios_base ::beg : début du fichier.
• ios_base ::cur : position courante du fichier.
• ios_base ::end : fin du fichier.
• Ces trois constantes sont ŕ utiliser en corrélation avec ios_base ::seekdir
Pour l'accčs direct, puisque nous travaillons octet par octet, il peut ętre utile de connaître la dimension exacte en octets des variables que nous utilisons pour envoyer ou recevoir des valeurs stockées dans les fichiers.
Il existe l'opérateur sizeof qui réalise ce calcul et qui peut ętre utilisé de trois façons différentes :
sizeof ( type ),
sizeof ( objet ),
sizeof objet ;
Choix du type de fichier
Ce que nous avons proposé comme nom de fichier jusqu'ŕ présent, correspondait ŕ un fichier sur le disque dur. Il est toutefois possible de communiquer avec d'autres ressources. Si vous tester le programme ci-dessous, vous allez vous apercevoir que les objets clavier et ecran remplacent cin et cout.
Ex :

En réalité, le nom de fichier « CON » est un mot réservé du systčme d'exploitation qui correspond ŕ la « console » de l'ordinateur, c'est-ŕ-dire, en entrée effectivement le clavier, et en sortie l'écran.
Il existe d'autres mots réservés du systčme d'exploitation, comme le montre le schéma ci-dessous :

Si vous travaillez sous Linux, Unix oů autre OS, voici un exemple :
ofstream fenetre '/dev/tty3´, ios::app) ;
Les flux de chaine
Plutôt que d'ętre en communication avec un périphérique quelconque, il est également possible de gérer les flux directement en mémoire centrale, tout en utilisant les méthodes et les constantes que nous venons de mettre en oeuvre. Ce stockage en mémoire se fait sous forme d'une chaîne de caractčres. Il sera ensuite possible de récupérer cette chaîne dans un objet de type string. Nous avons vu que dans les flux, grâce ŕ la redéfinition des opérateurs de redirection, il est possible de stocker et de récupérer des valeurs de type quelconque. Finalement, ce stockage en mémoire sera surtout utiliser pour transformer des valeurs de type quelconque, comme des entiers, des réels, etc. vers une chaîne de caractčres ou l'inverse.
Voici 3 classes qui sont spécialisé dans ce cas :
1. ostringstream : flot de sortie associé ŕ une chaîne de
caractčres.(hérite de ostream)
2. istringstream : flot d'entrée associé ŕ une chaîne de
caractčres. (hérite de istream)
3. stringstream : flot bidirectionnel associé ŕ une chaîne de
caractčres. (hérite de iostream)
De męme, voici des méthodes associées ŕ ces classes de gestion de chaînes de caractčres.
Tout le mécanisme interne du traitement de chaîne de caractčres est totalement caché (encapsulé) comme d'ailleurs pour la gestion des fichiers. Nous avons juste une méthode pour retourner la valeur de la chaîne de caractčres et les constructeurs qui disposent chacun de paramčtres par défaut pour permettre une utilisation la plus simple possible et pour correspondre aux cas les plus fréquents. Malgré tout, il existe des constructeurs qui permettent de construire le flot ŕ partir d'une chaîne de caractčres afin de proposer un formatage de cette chaîne vers d'autres types par la suite.
1. istringstream (ios_base::open_mode mode = ios_base::in) ; :
Constructeur en mode lecture par défaut.
2. istringstream (string chaîne, ios_base::open_mode mode =
ios_base::in) ; : Constructeur en mode lecture par défaut.
3. ostringstream (ios_base::open_mode mode = ios_base::out) ; :
Constructeur en mode écriture par défaut.
4. ostringstream (string chaîne, ios_base::open_mode mode =
ios_base::out) ; : Constructeur en mode écriture par
défaut.
5. stringstream (ios_base::open_mode mode = ios_base::in |
ios_base::out) ; : Constructeur en mode lecture et écriture
par défaut.
6. stringstream (string chaîne, ios_base::open_mode mode =
ios_base::in | ios_base::out) ; : Constructeur en mode
lecture et écriture par défaut.
7. string str () ; : renvoie la chaîne de caractčre stockée dans
le flux.
En conclusion, nous disposons, grâce ŕ ces classes, de tout un systčme de formatage pour passer d'un type quelconque vers une chaîne de caractčre et vice versa.
Changement de comportement par défaut
Le comportement par défaut de toute cette hiérarchie de la gestion des flux est déjŕ remarquable. Toutefois, ce serait encore mieux si nous pouvions avoir, par exemple, un affichage automatique sur les classes que nous créons. Il suffirait alors de proposer notre objet directement derričre l'opérateur de redirection pour que, effectivement, il s'affiche suivant notre désir.
En fait, il suffit de redéfinir l'opérateur « << » pour que ce fonctionnement s'applique. Attention toutefois, notre nouvelle classe ne faisant pas partie de la hiérarchie, nous sommes obligés de redéfinir cet opérateur en tant que fonction et non pas en tant que méthode. Il faudra donc proposer une relation d'amitié, ŕ moins que vous ne disposiez de toutes les méthodes requises pour la lecture des attributs. (Revoir l'étude de la redéfinition des opérateurs pour comprendre ces problčmes)
Ce que je viens de dire pour une communication vers l'extérieur s'applique, bien entendu, pour une lecture. Ainsi, il sera également possible de redéfinir l'opérateur « >> », et donc de prévoir, par exemple, une saisie clavier adaptée ŕ la classe étudiée.
Cette hiérarchie de classe intčgre le polymorphisme. Donc, lorsque nous redéfinirons les différents opérateurs, ils seront alors utiles aussi bien pour la console (le clavier et l'écran) que pour l'écriture ou la lecture dans un fichier (disque dur, imprimante, interface série, etc.) ou pour transformer notre classe en une chaîne de caractčres et vice versa.
Rappelons qu'ŕ droite d'un opérateur de redirection nous avons la classe ŕ traiter, ensuite ŕ gauche le flot concerné, et qu'une fois que l'opération s'est déroulée correctement l'opérateur renvoie également un objet flot, ce qui permet notamment les enchaînement des opérateurs de redirection.
Nous aurons donc les gabarits suivants :
ostream& operator << (ostream&, const NouvelleClasse&) ;
istream& operator >> (istream&, NouvelleClasse&) ;
Gestions des répertoires
Il peut ętre utile d'avoir des renseignements sur le contenu d'un répertoire afin de pouvoir contrôler l'existence d'un fichier. Malheureusement, cette possibilité n'a pas été intégrée directement dans les flux standard. Par contre, nous pouvons faire référence ŕ un certain nombre de fonctions qui s'occupent de ce genre de problčme et qui existe depuis le début du langage C. Nous allons en recenser quelques unes.
• int chdir (char * répertoire ) ; Changement du répertoire courant.
Retourne 0 si l'opération a réussi.
• int mkdir (char * répertoire ) ; Création d'un nouveau répertoire.
Retourne 0 si l'opération a réussi.
• int rmdir (char * répertoire ) ; Suppression du répertoire. Retourne 0
si l'opération a réussi.
• int getcurdir (int unité , char * répertoire ) ; Spécifie le nom du
répertoire courant en précisant l'unité de disque ( 0 : disque courant, 1 :
unité A, 3 : unité C, … ). Retourne 0 si l'opération a réussi.
• int getcwd (char * répertoire , int taille ) ; Spécifie le nom du
répertoire courant avec en plus le nom de l'unité. Il faut, par contre préciser la dimension
de la chaîne de caractčres. La constante MAXDIR contient le nombre de caractčres ŕ
réserver en toute sécurité.
• int getdisk (void) ; Retourne l'unité par défaut.
• int setdisk (int unité ) ; Changement de l'unité courante. Retourne 0 si
l'opération a réussi.
• int findfirst (char * répertoire , struct ffblk * info , intattribut ) ; Cherche le premier fichier du répertoire courant en spécifiant les filtres
désirés. Toutes les informations relatives ŕ un fichier sont stockées dans la structure de
type « ffblk ». Il est possible grâce ŕ attribut de spécifier le type de fichier
attendu (voir plus loin). Retourne 0 si l'opération a réussi.
• int findnext (struct ffblk * info ) ; Trouve le fichier suivant. Cette
fonction s'utilise ŕ la suite de la fonction findfirst et se sert de la structure initialisée
par cette derničre. Retourne 0 si le fichier a été trouvé, sinon, elle retourne -1 .
Structure ffblk qui donne toutes les informations sur l'en-tęte de fichier et la structure ftime


Attributs d ' un fichier < dir.h >
• FA_NORMAL : pour obtenir les fichiers normaux,
• FA_RONLY : pour obtenir les fichiers ŕ lecture seule,
• FA_HIDDEN : les fichiers cachés,
• FA_LABEL : l'étiquette de volume (soit le disque, soit la partition),
• FA_DIREC : les répertoires,
• FA_ARCH : les fichiers marqués ŕ archiver.
Pour terminer sur les flux et les fichiers, voici une petite illustration.


Définition
Męme lorsqu'un programme est au point, certaines circonstances exceptionnelles peuvent compromettre la poursuite de son exécution ; il peut s'agir par exemple de données incorrectes ou de la rencontre d'une fin de fichier prématurée (alors que nous avons besoin d'informations supplémentaires pour continuer le traitement).
Les exceptions sont donc des anomalies qu'un programme détecte en cours d'exécution, telles des divisions par 0, un accčs ŕ l'extérieur des bornes d'un tableau ou l'épuisement de la mémoire.
De telles exceptions sortent du fonctionnement normal du programme et requičrent de sa part une gestion immédiate.
Le langage C++ dispose d'un mécanisme trčs souple nommé gestion d'exception , qui permet ŕ la fois :
• de dissocier la détection d'une anomalie de son traitement,
• de séparer la gestion des anomalies du reste du code, donc de
contribuer ŕ la lisibilité des programmes.
Ce mécanisme s'effectue toujours en deux temps.
1. Nous avons d'abord, la détection de l'anomalie. Le
développeur doit alors avertir du disfonctionnement en
provoquant une rupture de séquence par le déclenchement
d'une exception correspondant ŕ l'anomalie. Cette phase
s'appelle souvent lever ou lancer une exception. Nous
lançons une exception par la directive throw.
2. Ensuite, si nous le désirons, nous pouvons nous occuper de
ce qui s'appelle la gestion d'exception, qui consiste ŕ
proposer un certain nombre d'actions pour gérer le problčme
lié ŕ une ou plusieurs anomalies. Généralement, nous
tentons d'abord d'effectuer le traitement prévu, et si cela se
passe mal, nous capturons l'exception lancée par la directive
throw. Nous proposons alors une alternative correspondant
au type de l'exception. En fait, et plus précisément, chaque
exception est caractérisée par un type, et le choix du bon
gestionnaire se fait en fonction de la nature de l'expression
mentionnée ŕ throw. Cette phase est réalisée par les
directives try ± catch (essayer et capturer).
Généralement, ces deux phases sont traitées par deux développeurs différents.
En effet, le premier construit les classes. Celui-ci doit alors prévoir tous les cas oů la classe peut ętre mal utilisée. Il doit donc proposer un ensemble d'exceptions correspondant aux disfonctionnements possibles.
Le second est celui qui utilise les classes. Celui-ci doit gérer les exceptions suivant l'utilisation qu'il fait de ces classes.
Ainsi, la gestion d'exception peut ętre totalement différente suivant l'utilisateur et surtout suivant le programme ŕ traiter.
Le fait d'avoir deux phases permet de simplifier considérablement la situation, chaque programmeur s'occupe de son propre problčme.
Détection des anomalies dans un fonctionnement d ' un programme correct
La premičre démarche, et ce n'est pas toujours la plus facile, consiste ŕ recenser toutes les anomalies possibles au sein d'une classe, dues généralement, ŕ une mauvaise manipulation de la part du programmeur qui l'utilise.
Pour illustrer ces propos, je vous propose de revenir sur l'étude d'un tableau d'entier.
Deux cas sont en réalité ŕ évité :
1. D'une part, une mauvaise proposition d'indice qui nous
envoie en dehors des limites du tableau.
2. D'autre part, une taille de tableau négative.
Quand ce genre de problčme arrive, il est préférable de tout arręter plutôt que de faire n'importe quoi et d'accéder ŕ une partie de la mémoire qui n'est pas prévue.
! Cette méthode mčne tout droit vers une écran bleu !
Pourrons nous levée une exception ?
Qu'est ce qu'une exception ?
Eventuellement, celui qui construit la classe pourrait envisager de proposer une solution dans le cas, par exemple, oů l'utilisateur tente d'accéder ŕ une case du tableau au delŕ des limites prévues.
Mais alors, que choisir comme indice. Le concepteur de la classe ne sait pas ce que l'utilisateur désire réellement faire. Il est préférable que le concepteur de la classe laisse l'initiative ŕ l'utilisateur et juste le prévenir qu'il y a un problčme.
Pour prévenir l'utilisateur, il faut lever une exception qui correspond ŕ l'anomalie. Pour cela, nous devons utiliser l'instruction throw suivi d'une valeur d'un type quelconque.
Nous pouvons, par exemple, proposer une valeur numérique entičre qui indique l'erreur correspondant ŕ l'anomalie, comme -1 pour le problčme de construction, et -2 pour le problčme lié ŕ l'indice.
Ceci dit, cette démarche n'est pas trčs élégante.
Que se passe-t-il lorsqu'une exception est levée ?
En fait, tout dépend si nous gérons l'exception ou pas (ŕ l'aide du bloc try - catch).
Si ce n'est pas le cas, l'exception provoque l'arręt pur et simple du programme.
De toute façon, ce n'est pas la peine d'aller plus loin, puisque si une exception est levée sans ętre gérée, nous nous trouvons alors dans une situation plutôt catastrophique.
Voici les trois rčgles ŕ suivre pour avoir un programme qui sont au point face aux multiples situation engendrées par l'opérateur.
1. Le développeur qui fabrique les classes doit s'occuper de
recenser l'ensemble des anomalies possibles et lance des
exceptions correspondant ŕ ces disfonctionnements.
2. Pour cela, il fabrique une classe d'erreur par type
d'anomalie.
3. Ensuite, c'est tout, son travail est terminé.
Interception et gestion des exceptions
Lorsqu'une exception est levée, plutôt que d'avoir un programme qui se termine de façon abrupte, il serait souhaitable de maîtriser la situation et de proposer une alternative de fonctionnement. Pour cela, il faut mettre en oeuvre ce que l'on appelle une gestion d'exception qui se déroule finalement en trois phases :
1. Tentative d'exécution d'un ensemble d'instructions,
2. Capture de l'exception, si un problčme est rencontré durant
cette tentative,
3. Gestion de l'exception en proposant une nouvelle suite
d'instructions.
Qu ' est ce qu ' une « tentative » ?
Pour intercepter et gérer les exceptions possibles, vous devez d'abord entourer les instructions qui sont susceptibles de lever des exceptions par un bloc try.
Un bloc try commence par le mot clé try suivi d'une séquence d'instructions entourées d'accolades.
Le bloc try est suivi d'une liste de gestionnaires appelés clauses catch.
En fait, le bloc try regroupe un ensemble d'instructions et leur associe un ensemble de gestionnaires pour gérer les exceptions que peuvent lever les instructions.
Si aucune exception ne survient, l'ensemble du code ŕ l'intérieur du bloc try est exécuté et les gestionnaires associés au bloc try sont ignorés.
Le programme exécute ensuite les instructions qui sont placées ŕ la suite des clauses catch.
Si une exception est levée ŕ l'intérieur d'un bloc try, les instructions qui suivent l'instruction lançant l'exception ne sont pas exécutées.
L'exécution du programme reprend dans la clause catch gérant l'exception.
Ici, la gestion des exceptions sont décrite dans le bloc catch.
Quand une exception est levée depuis des instructions dans un bloc try, la liste des clauses catch qui suit le bloc try est recherchée afin d'y trouver une clause catch qui soit capable de gérer l'exception.
Une clause catch se compose de trois parties :
1. le mot clé catch,
2. la déclaration d'un type unique ou d'un objet unique
entre parenthčses (appelée déclaration d'exception),
3. et un ensemble d'instructions dans une instruction
composée (accolades).
Si la clause catch est sélectionnée pour gérer une exception, l'instruction composée est exécutée.
Dčs qu'une clause catch a terminée son travail, l'exécution du programme continue sur l'instruction qui suit la derničre clause catch de la liste.
Le mécanisme de gestion des exceptions du C++ est dit sans reprise ; une fois l'exception gérée, l'exécution du programme ne reprend pas lŕ oů l'exception a été levée.
Comment peut se dérouler une clause « catch » ?
La recherche d'une clause catch pour gérer une exception levée se déroule ainsi. Si l'expression throw se trouve dans un bloc try, les clauses catch associées ŕ ce bloc sont examinées pour voir si l'une d'elles peut gérer l'exception.
Si une clause catch est détectée, l'exception est gérée. Si aucune clause catch n'est détectée, la recherche se poursuit dans le bloc try-catch de niveau supérieur (celui qui englobe le try-catch imbriqué).
Si une clause catch est trouvée dans ce nouveau bloc, l'exception est gérée sinon la recherche se poursuit ŕ un niveau encore supérieur. Ce processus se poursuit en remontant l'imbrication des blocs try-catch jusqu'ŕ ce qu'une clause catch pour l'exception soit trouvée. Dčs qu'une clause catch pouvant gérer l'exception est rencontrée, on entre dans la clause catch et l'exécution du programme continue dans ce gestionnaire.
Si aucun gestionnaire n'est trouvé, le programme appelle la fonction terminate() définie dans la bibliothčque du C++ standard. Cette fonction propose un comportement par défaut, qui appelle notamment la fonction abort() qui elle-męme indique que le programme se termine anormalement « Abnormal program termination ».
Comment propager une exception ?
Il est possible qu'une clause unique ne puisse pas gérer une exception complčtement.
Aprčs quelques actions correctives, une clause catch peut décider que l'exception sera gérée par un bloc try-catch de niveau supérieur.
Il suffit pour cela de propager l'exception.
Dans un gestionnaire, l'instruction throw (sans expression) retransmet (propage) l'exception au niveau englobant.

Si nous utilisons cette technique, il faut, bien entendu, que le bloc supérieur soit capable de capturer ce type d'exception et qu'il dispose donc du męme gestionnaire.
Existe - t-i l un gestionnaire pour toutes les exceptions ?
Au lieu de proposer un gestionnaire par type d'anomalies possibles, vous pouvez capturer toutes les exceptions dans une seule clause catch.
Cette clause catch possčde une déclaration d'exception de la forme, oů les trois points sont une ellipse.

ATTENTION, Ne pas y mettre en 1er. !!!!!!!!!!
Vous pouvez aussi combiner les exceptions en gérant quelques unes plus précisément et les autres de façon globale en utilisant alors la clause avec l'ellipse. Cela implique qui si un catch («) est combiné avec d'autres clauses catch, il sera toujours placé en dernier de la liste des gestionnaires d'exception.
En effet, les clauses catch sont examinées ŕ tour de rôle, dans l'ordre oů elles apparaissent ŕ la suite du bloc try.
Si les clauses catch particuličres se trouvaient aprčs la clause catch comportant l'ellipse, elles ne seraient jamais atteintes.
Le développeur qui utilise les classes ne s'occupe pas du tout de recenser les anomalies possibles.
Il doit juste proposer un certain nombre d'alternatives en gérant les exceptions qui peuvent ętre levées suivant les tentatives qu'il propose.
Vous remarquez que par cette disposition, chacun s'occupe de son propre domaine, ce qui simplifie notablement le travail.
Quelles sont les spécifications d 'exception ?
La spécification d'exception offre une solution pour lister les exceptions qu'une méthode peut lever en męme temps que la déclaration de la méthode. Elle assure (vérifié par le compilateur) que la méthode ne lance aucun autre type d'exception.
Une spécification d'exception suit la liste des paramčtres de la méthode. Elle est déclarée avec le mot clé throw, suivi d'une liste des types d'exception entourée de parenthčses.
Es t – ce tout cela peut s ' appliquée aux objets ?
Nous avons vus que la déclaration d'exception d'une clause catch peut ętre soit une déclaration de type, soit une déclaration d'objet.
Quand la déclaration d 'exception dans une clause catch déclare - t -elle un objet ?
Un objet sera déclaré lorsque nous devons obtenir la valeur ou manipuler l'objet exception créé par l'expression throw.
En effet, jusqu'ŕ présent, les classes d'exception que nous avons créées étaient réduites ŕ leurs plus simples expressions. Mais il s'agit de classes ŕ part entičre, comme les autres, et rien n'empęche de les créer de façon beaucoup plus sophistiquées avec un certain nombre d'attributs et de méthodes. Il est męme possible de structurer tout une hiérarchie de classes d'erreur.
Il peut ętre utile de fabriquer des classes d'erreur plus complčtes afin de stocker, par exemple, la valeur qui a provoqué l'erreur ainsi que les valeurs limites qu'impose le bon fonctionnement des classes normales.
La déclaration d'exception au niveau des clauses catch ressemble ŕ un paramčtre d'une méthode. Pour prévenir les copies inutiles d'objet de classes de grande taille, il est préférable que les déclarations d'exception soient déclarées en tant que référence.
Existe - t-il une hiérarchie dans les exception ?
Nous allons continuer nos investigations en proposant, cette fois-ci, une hiérarchie de classes polymorphiques, juste pour montrer toutes les possibilités et la souplesse du langage C++.
Dans l'exemple qui suit, nous construisons une classe de base abstraite oů il sera nécessaire de redéfinir la méthode getMessage qui délivrera le message correspondant ŕ l'objet levé.

Pour lever une exception, rien ne change, il suffit de créer l'objet relatif ŕ la classe qui correspond au défaut détecté.
Pour la capture, cela peut ętre, finalement, beaucoup plus simple. Il suffit, en effet, de faire une capture par rapport ŕ une référence sur la classe de base uniquement.
Le mécanisme du polymorphisme permettra de récupérer le bon objet exception.

Je remercie M. Remy Emmanuel, pour m' avoir donner l' autorisation de reprendre son cour, de le simplifier et de le publier sur l' Internet, plus particuličrement sur mon site.
BTS IRIS 2 ème année du Lycée Jean Monnet AURILLAC
Sources : http://pingouindetente.free.fr